
مدیریت کارآمد و کاوش Big Data برای کسب اطلاعات و دیدگاههای ارزشمند
کنترل نمودن Big Data
IBM BigInsights برای Apache Hadoop این امکان را در سازمانها فراهم مینماید که حجم زیادی از دادههای پیچیده و بزرگ را که جزو چالشهای اساسی سازمانها میباشد، به قسمتهای کوچکتر و قابل فهم تبدیل نماید. در سطحی بالاتر نیز میتوان این چالشها را به سه دسته اصلی تقسیم نمود که عبارتند از: کارایی عملیاتی، آنالیز پیشرفته و کشف و شناسایی.

کارایی عملیاتی
معماران به منظور مدیریت هر چه موثرتر عملکرد و همچنین تاثیر اقتصادی حجم دادههای در حال رشد، به ادغام نمودن کاراکترهای مختلف عملیاتی که درکنار یکدیگر قابل استفاده میباشند، پرداختند. برای مثال، مقدار زیادی از Cold Dataی موجود در انبار داده (Warehouse) را میتوان به جای یک فضای غیر فعال در یک محیط تحلیلی آرشیوبندی نمود.
BigInsights با مدرنسازی فضای ذخیره دادهها (نه جایگزینی آن) به بهبود کارایی عملیاتی کمک مینماید. این تکنولوژی را میتوان به عنوان یک آرشیو قابل جستجو یا دارای قابلیت Query استفاده نمود، که امکان ذخیرهسازی و تحلیل حجم زیادی از دادههای چندساختاری را بدون تحت فشار قرار دادن منبع داده برای سازمانها فراهم مینماید. همچنین BigInsights به عنوان یک Hub با قابلیت پیشپردازش یا با عنوان Landing Zone نیز میتواند مورد استفاده قرار گیرد. این ویژگی به سازمانها کمک مینماید تا دادهها را شناسایی و داراییهای با ارزش را تعیین نموده و آنها را به نحوی مقرون به صرفه استخراج نمایند. به علاوه، این تکنولوژی از آنالیز موردیِ حجم زیادی از دادهها برای کشف، شناسایی و تجزیه و تحلیل نیز پشتیبانی میکند.
تجزیه و تحلیل پیشرفته
برخی سازمانها علاوه بر افزایش کارایی عملیاتی، به دنبال اجرای تحلیلهای جدید و پیشرفته نیز میباشند، که در این مسیر با کمبود ابزار مناسب مواجه میگردند. لازم به ذکر است که با استفاده از BigInsights ، تجزیه و تحلیل گامی جدا از انجام فرآیند ذخیرهسازی دادهها نمیباشد، بلکه در ترکیب با InfoSphere Streams، امکان تجزیه و تحلیل دادهها به صورت Real Time را فراهم مینماید که از مدلهای سنتی این روش که بر اساس روش آنالیز دادهها در وضعیت Rest میباشد، استفاده میکند. به علاوه، BigInsights شامل قابلیتهای پیشرفته تحلیل متنی (Text-Analytic) و تسریعکنندههای از پیش دستهبندی شده (Prepackaged Accelerator) نیز میباشد. سازمانها میتوانند از قابلیتهای آنالیز که از پیش بر روی این سیستم تعریف شده است، جهت درک ساختار متن در اسنادِ بدون ساختار استفاده نمایند؛ همچنین میتوان Semantic Analysis را بر روی دادههای کلی اجرا نمود و به اطلاعات مناسب در مورد طیف وسیعی از منابع داده دست یافت.
کشف و شناسایی
رشد Big Data حتی در صورت قابل تشخیص بودن نیز ممکن است سازمانها را با مشکل مواجه نموده و شناسایی بخشهای مختلف از اطلاعات ارزشمند را دشوار سازد. BigInsights فضایی را ایجاد میکند که برای کشف و شناسایی روابط و همبستگی میان دادهها بسیار مناسب بوده و به ارائه دیدگاههای جدید و بهبود نتایج کسبوکار منتهی میگردد. کارشناسان داده (Data Scientists) قادرند دادههای خام حاصل از منابع Big Data را به همراه دادههای حاصل از منابع شرکت و چندین منبع دیگر در یک محیط Sandbox-Like (محیطی که برای تست نتایج قبل از اعمال آنها در محیط اصلی استفاده میشود) تجزیه و تحلیل نمایند و در پی آن، میتوانند هر گونه اطلاعات ارزشمند و جدید را با سایر دادهها ترکیب نموده تا به بهبود اطلاعات و دیدگاههای استراتژیک و عملیاتی و در نهایت اتخاذ تصمیمات کمک نماید.
سازمانها با استفاده از BigInsights میتوانند حجم زیادی از دادههایی که کمتر مورد توجه میباشند را برای کسب دیدگاههای ارزشمند، به شیوهای کارآمد، بهینه و مقیاسپذیر مورد بررسی قرار دهد.
ارائه Hadoop در سطح گسترده
BigInsights برای Hadoop به ترکیب Apache Hadoop متن باز، با نوآوریهای IBM میپردازد تا فرآیند پردازش و تحلیل دادهها به صورت Scale-Out را با قابلیتهای تحمل خطا (FT) و خودترمیمی (Resiliency) به صورت Built-In ارائه نماید. قابلیتهای مدیریت و اجرای ساده، ابزارهای قدرتمند توسعه دهنده و کارکردهای آنالیز قدرتمند توسط IBM ارائه شده است که میتواند پیچیدگی شروع کار با Hadoop را کاهش دهد.
یکی از چالشهای بزرگ در این زمینه، سطح بالای مهارتی است که در ارائه برنامههای کاربردی با استفاده از توزیع Hadoop به صورت متن باز یا Third Party نیاز میباشد. BigInsights با سادهسازی این فرایند برای افرادی که نیاز به پردازش این دادهها دارند (کاربران Spreadsheet و برنامهنویسان SQL)، به حل این مشکل پرداخته است تا ایجاد برنامههای کاربردی و دستیابی به اطلاعات نیز میسر گردد.
استفاده از BigInsights در Hadoop
BigInsights با قابلیت عملکرد در سطوح گسترده و یکپارچهسازی لازم برای دستیابی به الزامات مهم کسبوکار به ارتقای Hadoop متن باز میپردازد. سازمانها میتوانند وظایف آنالیز توزیعی در مقیاس بزرگ را بر روی کلاسترهای مربوط به سختافزار سرور به صورت مقرون به صرفه اجرا نمایند. این زیرساخت از چارچوب Hadoop MapReduce برای مواجهه با مجموعه BigData بهره میگیرد، بدین ترتیب که دادهها را در میان تعداد زیادی Node تقسیم نموده و پردازش دادهها را در میان محیطهای موازی هماهنگ مینماید. سیستم بعد از ذخیرهسازی دادهها در کلاستر توزیعشده، میتواند به نحوی موثر فرآیند جستجو یا Query و تحلیل دادهها را مدیریت نماید.
مفهوم Big SQL و کارکرد آن
در Big SQL به جای MapReduce، از موتور پردازش کاملا موازی SQL یا به عبارتی Massively Parallel Processing (Mpp) Sql Engine و به صورت مستقیم بر روی کلاستر (HDFS (Hadoop Distributed File System استفاده شده است، که عملکرد و قابلیت اجرای SQL را نسبت به Apache Hive 12 بهبود میبخشد. Big SQL، از SQL استاندارد استفاده نموده تا امکان دسترسی به Big Data را به همان شیوهی استفاده از سایر دادههای رابطهای برای کاربران فراهم نماید. همچنین BigInsights ، یک داشبورد تعاملی Built-In، برای تعامل کاربران نهایی با دادههای بزرگ ارائه مینماید. این مورد به واسطه Big SQL، به صورت یکپارچه با قابلیت هوشمندی کسبوکار در IBM Cognos برای داشبوردها و عملکردهای تعاملی ادغام میشود.
آزمونهای معیار عملکرد نشان میدهد که Big SQL میتواند فرآیند Query را به طورمیانگین 20 برابر سریعتر از Apache Hive 12 اجرا نموده و بهبود عملکرد برای Queryهای مجزا نیز تا 70 برابر سریعتر صورت میگیرد.
پشتیبانی فراگیر SQL: تکنولوژی Big SQL 3.0 به گونهای موفق Queryهای ALL 99 TPC-DS و ALL 22 TPC-H را بدون هیچگونه اصلاح اجرا مینماید که در مقابل آن، Apache Hive 12 صرفا قابلیت اجرای 43 مورد TPC-DS Query از 99 مورد را، بدون اصلاح داراست.
دسترسی به ستون و ردیف: Big SQL، کنترل دسترسی به ستون و ردیف یا “Fine-Grained Control” در RDBMS را امکانپذیر مینماید.
دسترسی یکپارچه به دادهها: Big SQL میتواند در مقایسه با BigInsights، دسترسی بیشتری به دادهها ایجاد کند. دسترسی یکپارچه این امکان را برای کاربران فراهم مینماید تا درخواستهای توزیعی خود را به چندین منبع داده در یک SQL یکسان ارسال نمایند.
مدیران شبکه کار نصب این پلتفرم را با یک ابزار گرافیکی شروع مینمایند که بدین ترتیب آنها را برای تعیین اجزای مورد نیاز برای نصب و نحوه پیکربندی پلتفرم هدایت میکند. پیشرفت فرآیند نصب به صورت Real Time گزارش شده و قابلیتی برای کنترل صحت عملکرد به صورت Built-In نیز طراحی میشود تا موفقیت فرآیند نصب به صورت خودکار تایید شود. این ویژگیهای پیشرفته برای نصب میتواند زمان مورد نیاز برای فرآیند نصب و تنظیم را به حداقل رسانده و بدین ترتیب، زمانِ مدیران را برای کار کردن روی پروژههای مهم و حیاتی آزاد نماید.
وقتی کلاستر Hadoop در جای صحیح و مناسب استفاده شود، ویژگیهای کارآمدی برای مدیریت کسبوکار، کنترل وظایف BigInsights ، مانیتورینگ شاخصهای عملکرد کلیدی، Roleهای کاربر و امنیت در اختیار سازمانها قرار میگیرد. علاوه بر این، کارکنان واحدهای فنی نیز میتوانند، به راحتی فرآیند ایجاد، واگذاری و لغو وظایف را مدیریت نمایند، در عین حال میتوانند از جریان بارکاری از طریق داشبوردهای یکپارچه وضعیت شغلی، Logها و سیستمهای مانیتورینگ که جزئیاتی را در مورد پیکربندی، وظایف، اقدامات و سایر اطلاعات مهم و حیاتی ارائه مینماید، مطلع گردند. به علاوه این تکنولوژی به ارائه ویژگیهای اجرایی برای Hadoop Distributed File System یا به اختصار HDFS و (IBM GPFS File Placement Optimizer (FPO، برنامههای کاربردی Big Data، مدیریت کلاستر و MapReduce Jobs میپردازد.
همانطور که در شکل زیر نشان داده شده است، BigInsights برای Hadoop میتواند چندین قابلیت در سطح گسترده را ارائه نماید. در بخشهای بعدی هر یک از قابلیتها به تفضیل ارائه میگردند.
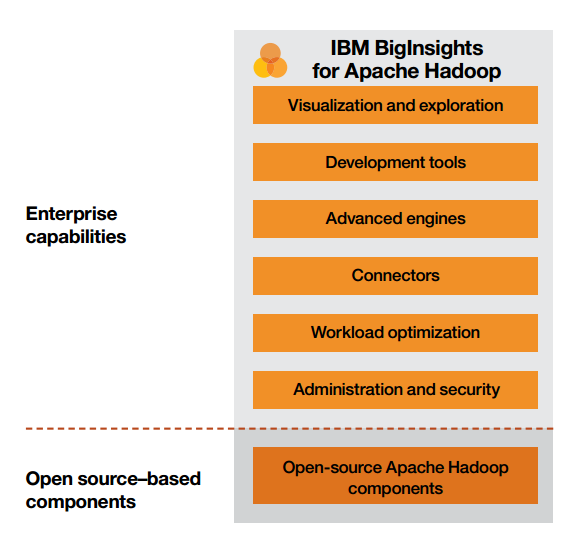
BigInsights ، قابلیتهایی را در سطح گسترده به اجزای متن باز اضافه مینماید.
ــــــــــــــــــــــــــــــــــــــــــــ
بررسی IBM BigInsights برای Apache Hadoop – قسمت اول
بررسی IBM BigInsights برای Apache Hadoop – قسمت دوم
بررسی IBM BigInsights برای Apache Hadoop – قسمت سوم (پایانی)
