
بازیابی از حادثه، Disaster recovery یا DR توانایی بازیابی و ادامهی برنامههای مهم سازمان را از بلایای طبیعی یا بلایای ایجاد شده توسط انسان است. این جزئی از استراتژی تداوم کسب و کار کلی هر سازمان بزرگی است که برای حفظ تداوم عملیات تجاری در طول رویدادهای نامطلوب بزرگ طراحی شده است.

Region Failure معمولاً با استفاده از اصطلاحات Recovery Point Objective یا RPO وRecovery Time Objective یا RTO بیان میشود. RPO معیاری است که نشان میدهد چقدر از دادههای پایدار پشتیبانگیری کرده و یا عکسهای فوری میگیرید. در واقع، RPO مقدار دادههایی را نشان میدهد که پس از قطع شدن از بین خواهند رفت و یا باید دوباره وارد شوند.
رویکردهای راهکار DR
RTO میزان downtimeای است که یک سازمان میتواند تحمل کند. RTO به این سؤال پاسخ میدهد که «پس از اطلاع از اختلال در کسب و کار چقدر طول میکشد تا سیستم ما بهبود یابد؟» روشهای مختلفی برای بازیابی فاجعه وجود دارد. هر گزینه، مانند هر چیز دیگر، دارای مزایا و معایب خاص خود است و ما باید بادقت مناسبترین راهکار را انتخاب و آن را با نیازهای خود تطبیق دهیم. در این مقاله، تعدادی از رویکردهای راهکار DR را توضیح، و الزامات اولیه برای هر یک را شرح خواهیم داد و در مورد ملاحظات اساسی در سطوح مختلف بحث خواهیم کرد: برنامهها و خدمات (هم در سمت توسعهدهنده و هم در سمت کاربر)
- کلاسترRed Hat OpenShift/Kubernetes
- زیرساخت
- ذخیرهسازی
- شبکه
- کلاسترهای جداگانه
- راهکار بازیابی از حادثهی مبتنی بر اتصال شبکهی لایه 3
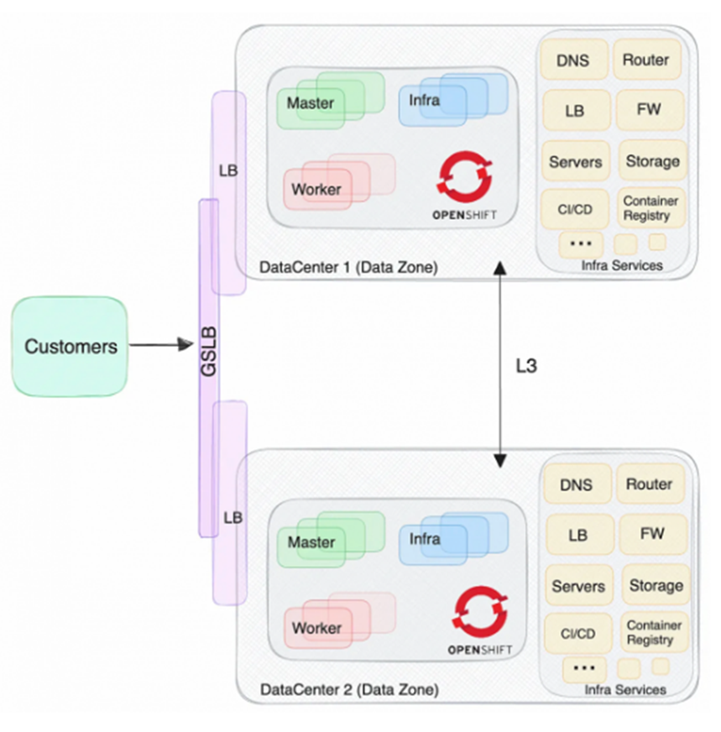
تصویر زیر گزینه با استفاده از اتصال شبکهی لایه 3 را نمایش میدهد.
فرضیات:
شبکه: اتصال مرکز داده،Data Center Interconnect یا DCI بین سایتها یک اتصالِ شبکهی لایه 3 میباشد.
کلاسترopenshift: کلاستر openshift مجزا برای سایت ثانویه
بیشتر بخوانید: بررسی دسترسیپذیری بالا و Disaster Recovery در طراحی SCOM
کلاستر ثانویه: باید جایگزین کلاستر تولید مانند همان نسخهی کلاستر، معماری، امنیت، بارگذاری دادهها، شبکه، منابع، گرهها و غیره باشد که برنامهها را مدیریت میکند.
متعادل کنندهی بار، Load balancer یا LB: به عنوان بخشی از خدمات زیرساخت برنامهریزی شده است که هر سایت دارای متعادلکنندهی جداگانه باشد و از جملهی آنها استفاده از ماژول متعادل کنندهی بار سرور جهانی GSLBمیباشد. بر اساس این راهکار، که مسئولیت لایهی شبکه است، در صورت لزوم یک تغییر مسیر به سایت ثانویه انجام خواهد شد.
برنامه: برنامه در کلاسترهای اصلی و ثانویه دقیقا به همان شیوه مستقر و به روز میشود.
ذخیرهسازی: راهکاری است برای تکثیر دادههای مورد نیاز؛ برای مثال برای برنامهها/ پادهایی با حجم مداوم، persistent volume claim یا PVC، رابط ذخیرهسازی کانتینر یا CSI باید انتقال اطلاعات به سایت ثانویه را مدیریت کند؛ مثلاً Red Hat CSI OpenShift Data Foundation دو گزینه دارد: Regional-DR یا Metro DR. علاوه بر این، ما میتوانیم یک رویکرد بازیابی فاجعه COLD را اتخاذ کنیم و یک راهکار پشتیبانگیری و بازیابی مانند
Red Hat OpenShift Application Data Protection یا OADP را بر اساس OpenShift API پیادهسازی کنیم. با این حال، مهم است که RTO، RPO و از دست دادن دادههای ممکن را در نظر بگیرید. هدف ما این است که مطمئن شویم که در هنگام بروز یک فاجعه و هنگام انتقال به سایت ثانویه، این سوئیچ برای کاربر شفاف است.
بیشتر بخوانید: بررسی Disaster Recovery در OMS
خدمات زیرساخت: مؤلفههای زیرساختی مانند رجیستری کانتینر، سامانه نام دامنه Domain Name System یا DNS، متعادلکنندهی بار، فایروال، ابزارهای ادغام و یا تحویل پیوسته یا CI/CD و غیره که کلاستر OpenShift/Kubernetes مبتنی بر آن است باید افزوده و دارای معماری با دسترسی بالا یا HA باشد. به منظور اجتناب از وابستگی بین سایت اصلی و سایت ثانویه، اجزای زیرساخت نیز باید مجزا بوده و قابلیت مدیریت خود در هر سایت را داشته باشند.
تجربهی کاربر راهکار DR
برنامهها میتوانند از سامانه نام دامنه ثابت و واجد شرایط کلاستر استفاده کنند و برای سوئیچ بین کلاسترها، تغییر DNS باید از سوی کاربر صورت گیرد. اگر FQDN در کد برنامه باشد، کد منبع برنامه مورد نیاز است. برای ارائه تجربهای یکپارچهتر برای کاربران هنگام دسترسی به برنامه، میتوانیم از GSLB استفاده کرده و یا راهکاری دستی مانند یک رکوردcanonical name record یا CNAME را پیادهسازی کنیم.
در یک کلاستر OpenShift، ترافیک ورودی HTTP/HTTPS از دامنهی پیکربندی شده برای همه برنامهها استفاده میکند (*.apps.<domain>). برای دستیابی به راهکاری که در آن نامهای DNS برنامه مستقل از نام کلاستر باشد، میتوان این مراحل را دنبال کرد:
کار را با پیادهسازی دامنهی برنامههای جدید «جهانی» در سرور DNS شروع کرد.
در مرحله بعد، مطمئن شد که مسیرهای برنامه ها با دامنهی جدید مرتبط هستند.
ورودی ترافیک را از طریق یک GSLB خارجی هدایت کرد.
این رویکرد، فرآیند انتقال برنامهها بین کلاسترها را آسان و آن را برای کاربران سادهتر میکند.
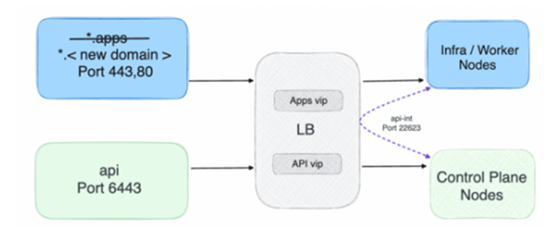
تصویری از فرآیند سادهسازی شده
با این کار دامنه apps پیشفرض حذف نمیشود، که به این معنا است که همچنان میتوانید از آن استفاده کنید.
مزایا و معایب
باید تأکید کنم که در صورت وقوع فاجعه، هدف اصلی ما انتقال یکپارچهی کاربران به سایت ثانویه است. وقتی صحبت از مدیریت دو کلاستر OpenShift مجزا میشود، چندین ملاحظهی مهم مطرح میشود:
استقرار برنامهها: بسیار مهم است که برنامهها هم در سایت اصلی و هم در سایت ثانویه به طور همزمان مستقر شوند. این هماهنگسازی را میتوان از طریق فرآیندهای CI/CD به دستآورد، که استقرار مداوم در هر سایت را امکانپذیر میسازد. در غیر این صورت، اگر این امکانپذیر نباشد، می توانیم رویکرد بازیابی فاجعه COLD را اتخاذ کنیم و یک راهکار پشتیبانگیری و بازیابی مانند OADP را بر اساس OpenShift API پیادهسازی کنیم. با این حال، باز هم ضروری است که RTO، RPO و از دست دادن دادههای احتمالی را در نظر بگیریم.
تجربهی کاربر (ترافیک ورودی HTTP/HTTPS): برای ایجاد یک تجربهی یکپارچه برای کاربران هنگام دسترسی به برنامه، میتوانیم از GSLB استفاده کنیم یا راهکاری دستی مانند رکورد CNAME را پیادهسازی کنیم.
کلاستر OpenShift: کلاستر ثانویه باید بتواند جایگزین کلاستر تولیدی شود که برنامهها را مدیریت میکند. مانند همان نسخهی کلاستر، معماری، امنیت، بارگذاری دادهها، شبکه، منابع، گرهها و غیره.
شبکه: گیتوی پیش فرض DG یا Default Gateway جداگانه، شبکههای محلی مجازی یا VLAN، قوانین فایروال و غیره.
ذخیرهسازی: راهکار تکثیر داده را همانطور که در بالا توضیح داده شد، از طریق CSI، توسط برنامه یا با رویکرد بازیابی فاجعه COLD بر اساس OpenShift API اجرا کنید.
تأیید تغییرات: به لطف جداسازی کامل سایتها، میتوانیم به طور سیستماتیک و ایمنتر تغییرات زیرساختها، مانند ارتقاء، تنظیمات امنیتی، اپراتورهای جدید و موارد دیگر، را تأیید کنیم.
عدم وابستگی: در حالی که دربارهی برخی از نکات پیادهسازی پیچیده بحث کرده ایم، بسیار مهم است که یک مزیت کلیدی را در این سناریو به خاطر بسپاریم: مطلقاً هیچ وابستگیای بین سایتها وجود ندارد.
گزینهی دوم: Stretch Cluster
راهکار بازیابی از حادثه بر اساس لایه 2 اتصالِ شبکه
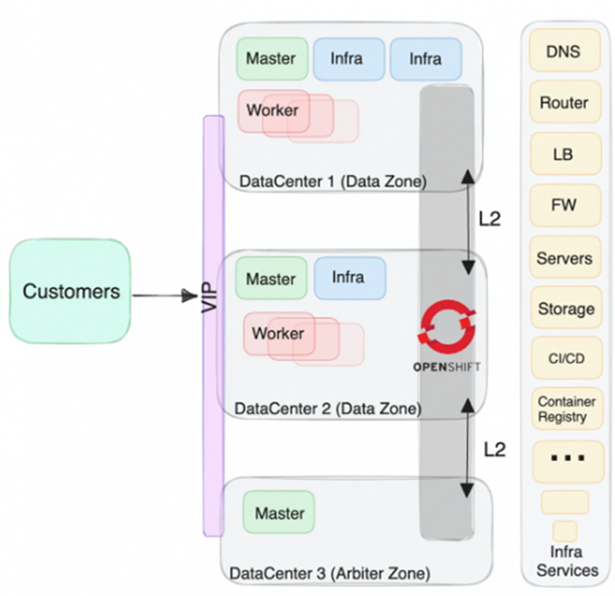
تصویرِ راهکار مبنی بر لایه 2 اتصال شبکه را در شکل زیر مشاهده میکنید.
فرضیات
شبکه: اتصال مرکز داده، Data Center Interconnect یا DCI بین سایت ها یک اتصال شبکه لایه 2 مانند مدل OSI با تاخیر کم است.
کلاستر OpenShift: استقرار کلاستر OpenShift بین مکانهای جغرافیایی مختلف کشیده شده است.
تجربهی کاربر (ترافیک ورودی HTTP/HTTPS): برنامهها میتوانند از FQDN ثابت کلاستر، بدون نیاز به تغییر DNS در یک فاجعه استفاده کنند.
خدمات زیرساخت: مؤلفههای زیرساختی مانند رجیستری کانتینر، سامانه نام دامنه Domain Name System یا DNS، متعادلکنندهی بار، فایروال، ابزارهای ادغام و یا تحویل پیوسته یا CI/CD و غیره که کلاستر Openshift و یا Kubernetes مبتنی بر آن است، باید افزوده و دارای معماری HA و راهکار DR باشند.
مزایا و معایب
هنگام استفاده از یک Stretch Cluster چندین نکتهی مهم مطرح میشود:
استقرار برنامهها: همان استقرار کلاستر Openshift بین مکانهای جغرافیایی مختلف کشیده میشود به طوری که برنامهها به طور خودکار در همهی سایتها مستقر میشوند.
تجربهی کاربر: برنامهها میتوانند از FQDN ثابت کلاستر، بدون نیاز به تغییر DNS در یک فاجعه، استفاده کنند.
کلاستر OpenShift: نیازی به نگرانی در مورد مسائل سازگاری بین مناطق نیست، چراکه یک کلاستر واحد کشیده شده است.
تأیید تغییرات: آزمایش تغییرات مرکزی به طور مستقیم در یک کلاستر تولید توصیه نمیشود. برای تأیید تغییراتِ زیرساخت مانند ارتقاء، تنظیماتِ امنیتی، اپراتورهای جدید و غیره، لازم است یک کلاستر جداگانه برای اهداف آزمایشی حفظ شود. توجه به این نکته مهم است که این کلاستر ممکن است کاملاً با کلاستر تولید، به ویژه از نظر اندازه، سازگار نباشد. بنابراین آزمایش و تأیید ممکن است نقص داشته باشد.
وابستگی: در این سناریو نوعی وابستگی بین سایتها هست، چراکه در واقع فقط یک کلاستر وجود دارد.
تأخیر کم: بین سایتهای جغرافیایی باید تأخیر کم باشد، چراکه etcd به تأخیر ذخیرهسازی و شبکه بسیار حساس است.
منطقهی میانجی: راهکار Stretch Cluster تداوم کسب و کار را با احتمال کمتر از دست دادن داده فراهم میکند، چراکه در دو مرکز داده با تأخیر کم و یک منطقهی میانجی کشیده شده است. در یک زیرساختِ قطعشده، فعال کردن یک منطقهی میانجی میتواند چالش برانگیز باشد، چراکه به طور مؤثر سایت مرکز دادهی جداگانه دیگری را نشان میدهد. در حالی که یک کلاستر Stretch شده را میتوان در دو سایت پیادهسازی کرد، باید توجه داشت که یکی از سایتها دو مدیر یا Master خواهد داشت. درصورت بروز فاجعهای که بر روی سایت دو مدیره تأثیر بگذارد، کلاستر به حالت Read Only تغییر میکند و زمان بازیابی برای تبدیل خواندن به نوشتن باید در نظر گرفته شود. هدف از منطقهی میانجی این است که از این سناریو جلوگیری کرده و همیشه اکثریت را فراهم کند؛ (احتمال از کار افتادن هر دو سایت به طور همزمان بسیار بعید است).
راهکارهای پشتیبانگیری
صرف نظر از انتخاب راهکار DR، همیشه توصیه میشود یک نسخهی پشتیبان داشته باشید این همان مفهوم COLD DR مباشد.که در اینجا سه نمونه از گزینههای پشتیبانگیری آورده شده است:
تهیهی یک نسخهی پشتیبان از etcd به صورت روزانه برای هر کلاستر به منظور فعال کردن بازیابیِ کلاستر در صورت لزوم.
COLD DR: یک راهکار پشتیبانگیری و بازیابی مبتنی بر OpenShift API برای حفاظت از دادهها OADP.
استفاده از Git برای مدیریت و ذخیرهی برنامهها، استقرارها، پیکربندی و غیره.
بازیابی از حادثه موضوعی بسیار مهم است چراکه مستقیماً بر تداوم عملیاتی و قابلیت خودترمیمی تجاری سازمان تأثیر میگذارد.
همانطور که گفته شد، راهکارها و رویکردهای متعددی برای اجرای راهکار DR وجود دارد. هنگام طراحی یک معماری، عوامل متعددی از جمله زیرساخت، الزامات سازمانی و مزایا و معایب گزینههای مختلف باید در نظر گرفته شوند. هدف نهایی ساختن یک معماری منطبق با نیازهای سازمان است، و فناوری به عنوان ابزاری حیاتی در استراتژی تداوم کسب و کار شما عمل میکند.
