
Block cloning امکان کپیکردن طیف وسیعی از فایل بایتها را از طرف یک برنامهی کاربردی به فایل سیستم میدهد، که در آن فایل، ممکن است مقصد همان فایل مبدا و یا متفاوت از آن باشد. متاسفانه عملیات کپی به جهت هزینهبر بودن خواندن و نوشتنِ دادههای فیزیکی مهم ، به صرفه نمیباشد.

Block Cloning در ReFS به جای خواندن و نوشتن فایلدیتا، Metadataهای کم اهمیتتر را کپی میکند. زیرا ReFS چندین فایل را قادر میسازد که کلاسترهای منطقی یکسان با فضای اختصاصیافته فیزیکی روی یک Volume را به اشتراک بگذارند. عملیات کپی فقط نیاز به Remap بخشی از یک فایل به مکان فیزیکی جداگانه و تبدیل عملیات پرهزینهی فیزیکی به عملیات سریع منطقی را دارد. این امر موجب انجام شدن سریعتر کپیها و تولید I/O کمتری در Storage میشود. بهبود این امر همچنین برای بارهای کاری مجازیسازی مفید است، زیرا عملیات merge کردن Checkpointهای .vhdx هنگام استفاده از عملیات Block Clone به طور چشمگیری افزایش مییابد. علاوه براین، به دلیل اینکه چندین فایل میتوانند دارای کلاسترهای منطقی مشترکی باشند، دادههای یکسان به صورت فیزیکی چندینبار ذخیره نمیشود و این امر موجب بهبود ظرفیت ذخیرهسازی میگردد.
نحوهی کار ReFS
Block Cloning در ReFS عملیات فایلدیتا را به عملیات Metadata تبدیل میکند. برای انجام این بهینهسازی، ReFS برای بخشهای کپی شده، Reference Countها را به Metedataی خود معرفی میکند. این Reference Count تعدادی فایل مجزای ثبت میکند، که به همان بخشهای فیزیکی ارجاع میدهند. این امر به چندین فایل اجازهی اشتراکگذاری دادهی فیزیکی یکسانی را میدهد.
با حفظ Reference Count برای هر کلاستر logical، فضای ایزوله و مجزا بین فایلها توسط ReFS از بین نمیبرد. Writeهایی که روی بخشهای مشترک انجام میشوند یک مکانیسم اختصاصی نوشتن را راهاندازی میکنند، بطوری که ReFS یک بخش جدید را برای نوشتههای ورودی اختصاص میدهد. این مکانیسم، یکپارچگی کلاسترهای منطقی مشترک را حفظ میکند.
به عنوان مثال اگر دو فایل X و Y وجود داشته باشد بطوریکه هر فایل از سه بخش تشکیل شده باشد و هر بخش با کلاستر منطقی جداگانهای ارتباط داشته باشد، وضعیت به صورت جدول زیر خواهد بود.
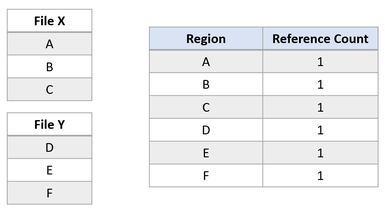
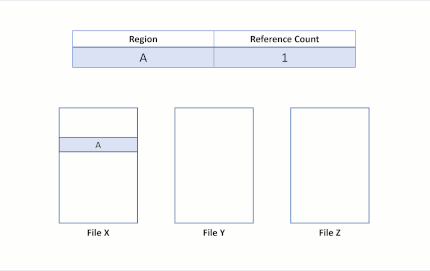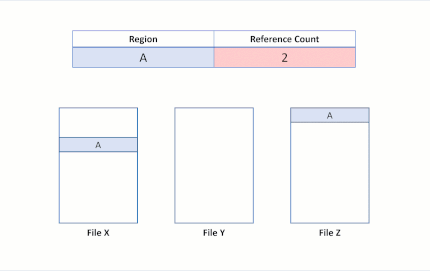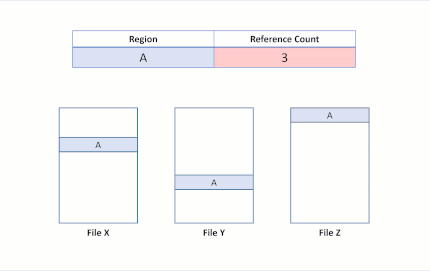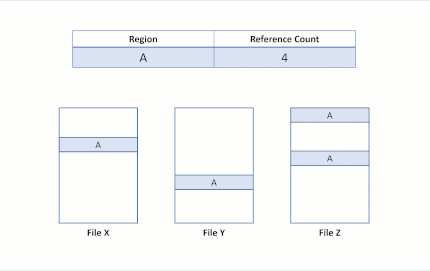
حالا اگر برنامهای کاربردی عملیات Block Clone را از فایل X به فایل Y اجرا کند، تا بخشهای A و B در Offset بخش E کپی شوند. وضعیت فایلسیستم بعدی به شکل جدول زیر درمیآید:
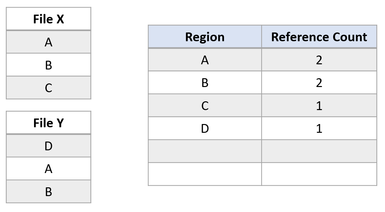
وضعیت فایل سیستم، نمایانگر یک عملیات duplication موفق از بخش Block Cloneشده میباشد. از آنجایی که ReFS صرفا این عملیات کپی را با ارتقای VCN به LCN Mapping انجام میدهد، هیچ Physical Dataیی خوانده و یا در فایل Y بازنویسی نمیشود. حالا فایل X و Y دارای کلاسترهای منطقی مشترکی هستند که تحت عنوان Reference Count در جدول مشخص شدهاند. از آنجاییکه هیچ دادهای به صورت فیزیکی کپی نشده بود، ReFS میزان مصرف ظرفیت را در حجم کاهش میدهد.
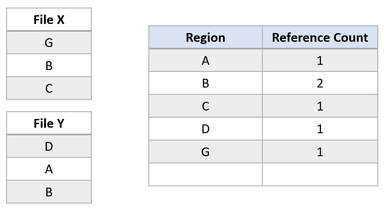
اگر برنامهای تلاش کند تا بخش A را در فایل X بازنویسی کند، ReFS بخش مشترک را تکثیر خواهد کرد، Reference Countها را به گونهای مناسب بروزرسانی خواهد نمود و نوشتههای ورودی را در بخشی که به تازگی تکثیر شده اجرا خواهد کرد. این امر تضمین میکند که ایزولهسازی بین فایلها حفظ گردد.
پس از ویرایش write، بخش B هنوز هم توسط هر دو فایل به اشتراک گذاشته میشود. قابل توجه است که اگر بخش A بزرگتر از کلاستر باشد، فقط کلاستر اصلاح شده میتواند تکرار گردد و بخش باقیمانده به اشتراک گذاشته شود.
محدودیتهای عملکرد Block Cloning در ReFS
- بخش منبع و مقصد باید در محدودهی کلاستر آغاز و پایان یابند.
- بخش Cloned باید کمتر از 4GB طول داشته باشد.
- بیشترین تعداد بخشهای فایل که میتوانند به بخش فیزیکی یکسان مرتبط شوند 64K است.
- بخش مقصد نباید فراتر از پایان فایل باشد. اگر برنامه نیاز به گسترش مقصد با دادهی Cloneشده داشته باشد، ابتدا باید وضعیت SetEndOfFile بررسی شود.
- اگر بخشهای منبع و مقصد در یک فایل واحد باشند، نباید با یکدیگر همپوشانی داشته باشند. (برنامه ممکن است با تقسیم عملیات Block Clone به چندین Block Cloneکه دیگر همپوشانی ندارند، ادامه پیدا کند.)
- فایلهای منبع و مقصد باید در یک حجم ReFS یکسان باشند.
- فایلهای منبع و مقصد باید تنظیمات Integrity Streams یکسانی داشته باشند.
- اگر فایل منبع بصورت پراکنده توزیع شده باشد، فایل مقصد هم باید پراکنده توزیع شود..
- عملیات Block Clone، Opportunistic Lockهای مشترک را که همچنین با نام Opportunistic Lock Level 2 شناخته میشود، حذف خواهد کرد.
Volume ReFS باید با ویندوز سرور 2016 فرمت شده باشد و اگر Failover Clustering در حال استفاده است، باید سطح عملکرد Clustering در زمان فرمت، ویندوز سرور 2016 یا جدیدتر باشد.
