نحوهی پاسخ vSphere HA و vSphere DRS به خرابیها در محیط های کلاستر شده چگونه است؟ در سری مقالات آشنایی با VMware vSphere Metro Storage Cluster یا vMSC و بررسی قابلیت های آن – قسمت اول و دوم در مورد vMSC و در مورد اینکه vMSC چیست؟ و قابلیت های آن به عنوان یک پیکربندی Storage بهخصوص که معمولاً تحت عنوان کلاسترهای Stretched Storage یا کلاسترهای Metro Storage شناخته میشود صحبت کردیم و در مورد مزایای راهکار کلاستر Stretched بحث کردیم و به تعدادی سناریو های مختلف پرداختیم.

حال یک سناریو دیگر را بررسی می کنیم در این سناریو، تنها یک Disk Shelf در دیتاسنتر Frimley دچار خرابی شده است. پردازندهی Storage خرابی را شناسایی کرده است و بلافاصله از Disk Shelf اصلی در دیتاسنتر Frimley به Mirror Copy در دیتاسنتر Bluefin رفته است. به غیر از افزایش کوتاهی در زمان پاسخدهی I/O، هیچ تأثیر قابلتوجهی در هیچیک از VMها رخ نمیدهد. راهکار Storage به طور کامل این سناریو را شناسایی کرده و به آن رسیدگی میکند. نیازی به اسکن مجدد Datastore یا HBAها نیست، زیرا Switchover یکپارچه است و LUNها از نظر vSphere Host مشابه هستند.
خرابی Storage کامل در دیتاسنتر Frimley
در این سناریو، خرابی کامل سیستم Storage در دیتاسنتر Frimley رخ داده است.
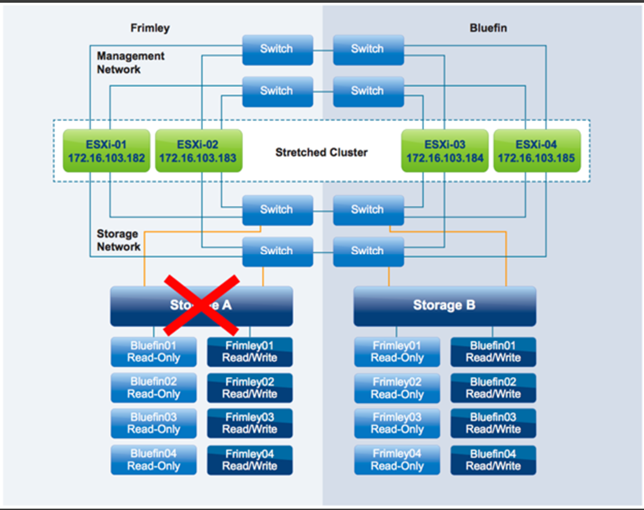
وقتی سیستم Storage به طور کامل در دیتاسنتر Frimley دچار خرابی شود، باید بهطور دستی یک دستور Take Over اجرا گردد. همانطور که قبلاً شرح داده شد، برای توضیح این رفتار از یک پیکربندی NetApp MetroCluster استفاده شده است. این دستور Take Over مخصوص محیطهای NetApp است و بسته به سیستم Storageی که به کار رفته است، فرایند موردنیاز میتواند متفاوت باشد. پس از اینکه این دستور اجرا شد، کپی Mirrored و Read-Only از هر Datastore خراب به Read/Write تنظیم شده و بلافاصله قابلدسترسی میشود.
از نظر VM، این Failover یکپارچه است: کنترلرهای Storage به آن رسیدگی میکنند و نیاز به هیچ اقدامی از طرف ادمین vSphere یا Storage نیست. کل I/O اکنون از طریق ارتباط داخل سایت به دیتاسنتر دیگر میرسد، زیرا VMها همچنان در دیتاسنتر Frimley اجرا میشوند، درحالیکه Datastoreهای آنها فقط در دیتاسنتر Bluefin قابلدسترسی هستند.
vSphere HA این نوع از خرابی را شناسایی نمیکند، هرچند ممکن است Datastore Heartbeat موقتاً از دست برود، vSphere HA اقدامی انجام نمیدهد زیرا Agnet اصلی vSphere HA فقط زمانی Datastore Heartbeat را چک میکند که Heartbeat شبکه به مدت سه ثانیه دریافت نشده باشد. ازآنجاییکه Heartbeat شبکه در طول خرابی Storage همچنان در دسترس میماند، VSphere HA برای شروع هیچ Restart موردنیاز نیست.
از دست رفتن دائمی دستگاه
در سناریویی که در شکل بالا نمایش داده شده است، از دست رفتن دائمی دستگاه یا PDL رخ داده است، زیرا Datastoreی به نام Frimley01 برای ESXi-01 و ESXi-02 آفلاین شده است. سناریوهای PDL در پیکربندیهای یکپارچه متداول نیستند و احتمال رخ دادن آنها در یک پیکربندی vMSC غیر یکپارچه بیشتر است. بااینحال، ممکن است یک سناریوی PDL زمانی رخ دهد که پیکربندی یک گروه Storage تغییر کرده باشد، مثل سناریویی که توصیف شد.
سناریو از دست رفتن دائمی دستگاه
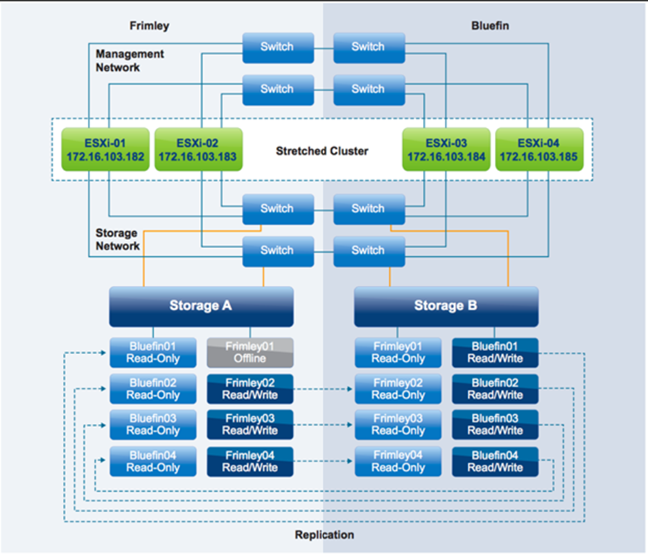
وقتی PDL رخ میدهد، VMهایی که روی Datastore Frimley01 روی Hostهای ESXi-01 و ESXi-02 اجرا میشوند، بلافاصله قطع میگردند. سپس توسط vSphere HA روی Hostهایی درون کلاستر که در این سناریو به Datastore، ESXi-03 و ESXi-04 دسترسی دارند، Restart میشوند.
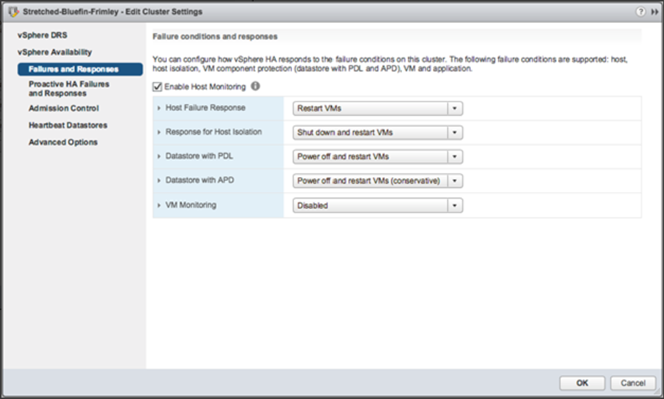
VMware پیشنهاد میکند که گزینهی Response for Datastore with Permanent Device Loss یا PDL به Power off and restart VMs پیکربندی گردد. این تنظیمات باعث میشود که اقدامات مناسبی برای زمانی که شرایط PDL رخ میدهد، اتخاذ گردد. پیکربندی صحیح در شکل زیر نمایش داده شده است.
خرابی کامل رایانش در دیتاسنتر Frimley
در این سناریو، یک خرابی کامل رایانش در دیتاسنتر Frimley رخ داده است.
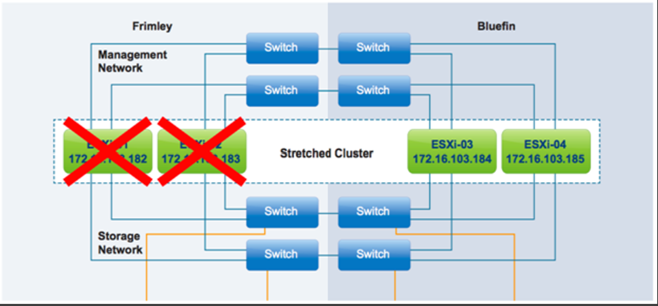
نتیجه این است که تمام VMها با موفقیت در دیتاسنتر Bluefin می توانند Restart شوند. در زمان خرابی کامل رایانش در دیتاسنتر Frimley، vSphere HA اصلی در آنجا قرار دارد. پس از اینکه Hostها در دیتاسنتر Bluefin تشخیص دادند که هیچ Heartbeat شبکهای دریافت نشده است، یک فرایند انتخاب آغاز شد. در حدود 20 ثانیه، یک vSphere HA اصلی جدید از بین Hostهای باقی مانده انتخاب می شود، سپس مشخص می شود که کدام Hostها دچار خرابی شدهاند و کدام VMها تحت تأثیر این خرابی قرار گرفتهاند. به دلیل اینکه تمام Hostها در سایت دیگر دچار خرابی شدند و تمام VMهایی که روی آنها قرار داشتند تحت تأثیر قرار گرفتند، vSphere HA ریاستارت این VMها را شروع می کند. vSphere HA در ابتدا Restart را برنامهریزی میکند که تنها زمانی میتواند موفق شود که منابع رزرونشدهی کافی در دسترس باشند. برای اطمینان حاصل کردن از این امر، کنترل پذیرش vSphere HA فعال می شود.
vSphere HA میتواند 32 ریاستارت همزمان را روی یک Host واحد آغاز کند و میزان تأخیر پایینی را برای ریاستارت اکثر محیطها فراهم نماید. میتوان ترتیب ریاستارت را برای VMهایی که از ویژگی VM Overrides بهره میبرند، مشخص نمود و یک پالیسی باید برای هر VM تنظیم گردد. مشخص شده است که باید به این پالیسیها عمل شود؛ VMها با بالاترین اولویت در ابتدا آغاز به کار میکنند، سپس VMهایی با اولویت بالا، متوسط، پایین و پایینترین اولویت.
بیشتر بخوانید: مزایای پیاده سازی vSphere Cluster و بررسی امکانات HA در مجازی سازی
بهعنوان بخشی از تست، Hostها در دیتاسنتر Frimley دوباره روشن شدند. به محض اینکه vSphere DRS تشخیص داد که این Hostها قابلدسترسی هستند، اجرای یک vSphere DRS آغاز می شود. ازآنجاییکه اجرای vSphere DRS در ابتدا فقط نقض قاعدهی وابستگی vSphere DRS را اصلاح میکند، تا قبل از اجرای کامل vSphere DRS، عدم تعادل منابع اصلاح نشود. بهطور پیشفرض vSphere DRS هر پنج دقیقه یا وقتی که VMها خاموش یا روشن میشوند، از طریق استفاده از vSphere Web Client آغاز میشود.
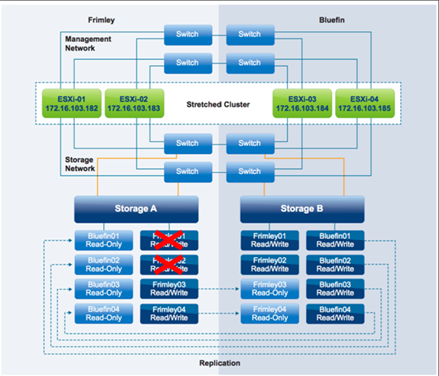
از دست رفتن دیتاسنتر Frimley
در این سناریو، یک خرابی کامل در دیتاسنتر Frimley شبیهسازی میشود.
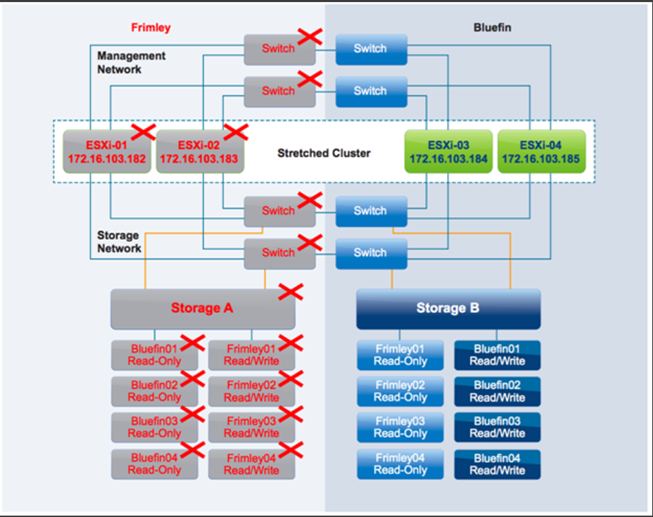
نتیجه این است که تمام VMها با موفقیت در دیتاسنتر Bluefin ریاستارت میشوند، در این سناریو، Hostها در دیتاسنتر Bluefin ارتباط را با vSphere HA اصلی از دست دادند و یک vSphere HA اصلی جدید را انتخاب کردند. ازآنجاییکه سیستم Storage دچار خرابی شده اند، باید دوباره به دلیل فرایند مخصوص به NetApp یک دستور Take Over در سایت سالم آغاز شود. پس از آغاز دستور Take Over، vSphere HA اصلی جدید به فایلهای هر Datastore که vSphere HA برای ضبط VMهای محافظت شده از آن استفاده میکرد، دسترسی پیدا می کند، سپس vSphere HA اصلی سعی کرد VMهایی را که روی Hostهای سالم در دیتاسنتر Bluefin اجرا نمیشدند را ریاستارت کند. در سناریوی ما، تمام VMها در عرض دو دقیقه پس از خرابی ریاستارت می شوند و دوباره کاملاً قابلدسترسی و عملیاتی خواهند بود.
بهطور پیشفرض vSphere HA پس از سی دقیقه تلاش برای راهاندازی، یک VM را قطع میکند. اگر تیم Storage در آن چارچوب زمانی یک دستور Takeover را صادر نکند، ادمین vSphere باید بهصورت دستی پس از اینکه Storage قابلدسترسی شد، VMها را روشن کند.
وقتی کلاسترهای Stretched به درستی عمل کنند و معماری شوند، راهکاری بسیار عالی برای افزایش قابلیت خودترمیمی هستند و تحرکپذیری بار کاری بین سایتی را فراهم میکنند. اما همیشه در مورد سناریوهای خرابی و انواع مختلف پاسخها هم از لایهی vSphere و هم لایه Storage، سردرگمیهایی وجود داشته است. در مقالات با موضوع آشنایی با VMware vSphere Metro Storage Cluster یا vMSC و بررسی قابلیت های آن – قسمت اول و دوم و این مقاله تلاش شد که نحوهی پاسخ vSphere HA و vSphere DRS به خرابیهای بهخصوص در یک محیط کلاستر Stretched شرح داده شود و پیشنهاداتی برای پیکربندی یک کلاستر vSphere در این نوع از محیط ارائه گردد. این مقاله اهمیت وابستگی سایت، نقشی که توسط vSphere HA و قواعد DRS Cluster و گروهها بازی میشود را نشان داد، همچنین بیان شد که vSphere HA چگونه با آن قواعد و گروهها تعامل میکند و کاربران چگونه باید اطمینان حاصل کنند که منطق اعمال شده توسط آن قواعد و گروهها در طول زمان حفظ میگردد تا قابلیت اطمینان و قابل پیشبینی بودن کلاستر فراهم گردد.
