
در قسمت های اول و دوم از سری مقاله های IBM DataWorks ، مفهوم این تکنولوژی و دلایل استفاده از آن را مورد بررسی قرار دادیم و به امنیت بالای آن پرداختیم؛ در این مقاله نیز به موارد استفاده IBM DataWorks در کنار سایر محصولات شرکت IBM می پردازیم.

Apache Spark: فاکتوری برای قدرت و عملکرد
IBM DataWorks ، با دارا بودن مجموعه گستردهای از کانکتورها به منابع دادههای مختلف مانند dashDB، IBM DB2، Cloudera Impala، Apache Hive و Sybase، راهکاری قدرتمند برای انتقال دادهها محسوب میشود. بهرحال، فعالیت در تعداد زیادی از منابع داده در کنار حفظ عملکرد و مقیاس پذیری، مستلزم انتقال داده در حجم انبوه میباشد، به همین دلیل DataWorks از Apache Spark به عنوان موتور متنباز پیشرو برای پردازش Big Data استفاده مینماید.

Spark، به عنوان یک ابزار عالی و قابل دسترسی، روند رو به رشدی را طی نموده تا قابلیتهای بیشتری را جهت پردازش دادهها و یادگیری ماشینی ارائه نماید. این تکنولوژی با استفاده از یک مدل محاسباتی کلاستر بر روی یک مدل پردازش دادهی Apache Hadoop، گسترش و توسعه مییابد و دارای یک واسط برنامهنویسی ساده میباشد که آن را به گزینهای ایدهال برای دادههای درجریان (Streaming Data) و همچنین بارهای کاری جستجوی متوالی تبدیل مینماید که در Mobile App و Web App امروزی مشترک میباشد. عملکرد، انعطافپذیری و سهولت کاربری Spark، آن را به گزینهای مناسب برای پاسخدهی سریعتر، از مجموعه دادههای حجیمتر تبدیل مینماید.
در DataWorks، موتور Spark در پشت صحنه فعالیت مینماید تا تغییر و دستکاری سریع دادهها در مقیاس بزرگ را به صورت Real-Time میسر نماید. کاربر به راحتی Log In میشود، اتصال را ایجاد نموده و یک Gateway ایمن را جهت اتصال به دادهها در On-Premise یا Cloud تعیین مینماید. لازم به ذکر است که تمامی این مراحل برای کاربران غیرقابل مشاهده میباشد، سپس DataWorks به کلاستر Spark متصل میگردد تا دادهها را به سرعت از منبع بارگذاری نموده و دشواریهای مربوط به دستهبندی، ترتیبدهی مجدد ، دستکاری ستونها و موارد دیگر را مورد توجه قرار دهد. DataWorks سپس فرآیندهای مبتنی بر Spark را به عنوان فعالیتهایی قابل تکرار بر روی همه برنامهها ذخیره مینماید. بدین ترتیب، کاربر میتواند بر ارائه سریعتر نتایج کسبوکار از دادههای جدید، در مقایسه با گردآوری دستی دادهها تمرکز بیشتری نماید. با DataWorks و Spark، حتی کاربران در سطح مبتدی هم میتوانند حجم زیادی از دادههای مبتنی بر Cloud یا On-Premise را به راحتی و به صورت ایمن مدیریت نمایند.
DataWorks :IBM Watson Analytics در سطح عملکرد
موفقیت زودهنگام DataWorks به دلیل ویژگیهای آمادهسازی یکپارچه دادهها و همچنین فرآیندهای یکپارچهسازی سرویس Cloud میباشد که توسط IBM Watson Analytics به عنوان ابزار تجزیه و تحلیل و تصویرسازی پیشرو در صنعت ارائه شده است. DataWorks در Watson Analytics گنجانده شده و برای تحلیلگران کسبوکار که به دنبال بهبود کیفیت دادهها قبل از تحلیل و ارائه گزارش میباشند، یک تجربه مجزا، یکپارچه و متناسب با شرایط را ایجاد میکند.

Watson Analytics پس از ادغام با DataWorks به قابلیتهای جدیدی در عملکرد دست یافت که برخی از آنها عبارتند از:
-
دسترسی به چندین منبع داده در شرکت:
در حال حاضر میتوان برای تجزیه و تحلیل دقیقتر و ارائه گزارش (Business intelligence (BI در Watson Analytics به منابع داده بیشتری در Cloud و یا در On-Premise شامل Amazon Redshift، Apache Hive، Cloudera Impala، IBM DB2، IBM Informix، IBM Netezza، IBM SQL Database، IBM dashDB، Microsoft Azure، Microsoft SQL Server، MySQL، Oracle، Pivotal Greenplum، PostgresSQL، Salesforce.com، Sybase و Sybase IQ دسترسی یافت.
-
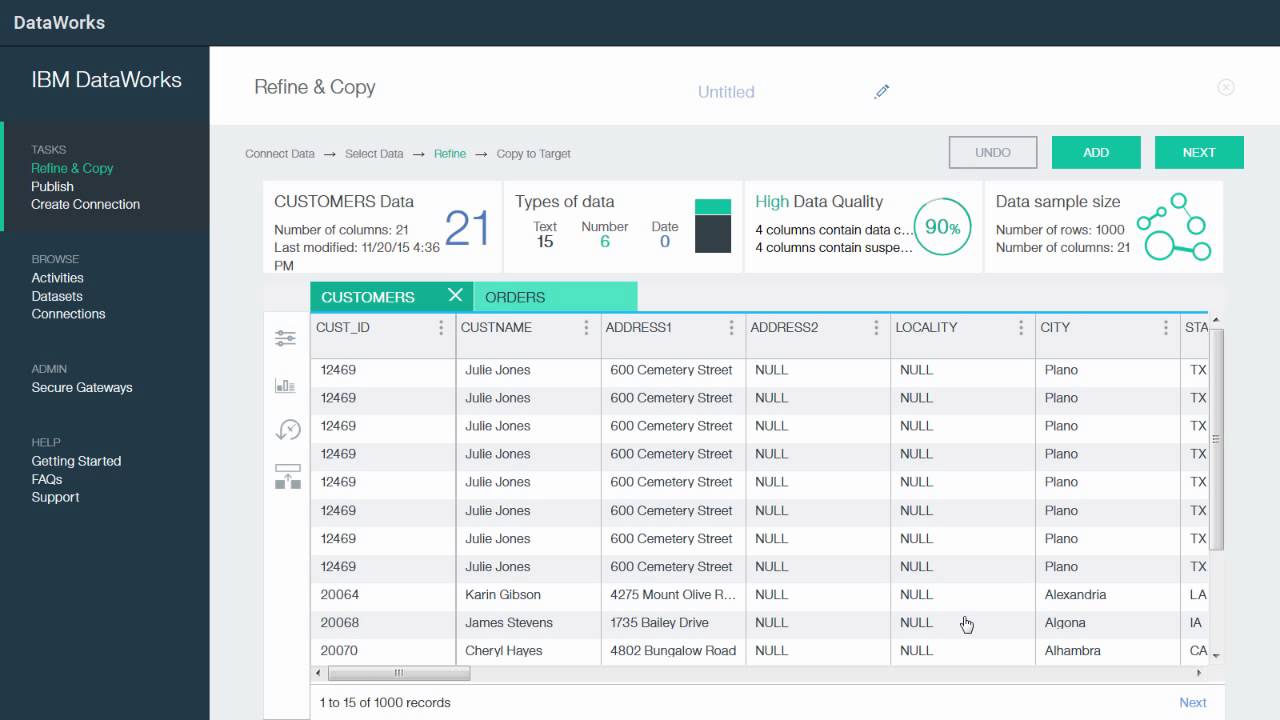
شکلدهی قبل از بارگذاری:
کاربران میتوانند تصمیم بگیرند که دادهها را از منابع خود، بدون هیچگونه تغییری بر روی Watson Analytics بارگذاری نمایند و یا اینکه قبل از Load آنرا اصلاح کنند. این شکلدهی به کاربران اجازه میدهد تا کیفیت دادههای خود را ارزیابی نمایند، پیشنمایش آن را مشاهده و آن را بر اساس مقادیر ستونها فیلتر کنند، ستونهای غیر ضروری را حذف و دادههای مربوط به منابع مختلف را با هم ترکیب نمایند.
-
دسترسی ایمن به دادههای پشت فایروال:
با Gateway ایمن، امکان دسترسی به دادههای پشت فایروال در DataWorks برای کاربر فراهم میشود. بدین ترتیب مدیران میتوانند یکSSH Tunnel را برای سرورهای موجود در یک فضای دسترسی کنترلشده، ایجاد نموده و اتصالاتی را به منابع داده On-Premise و سایر منابع ایمنشده ایجاد نمایند.
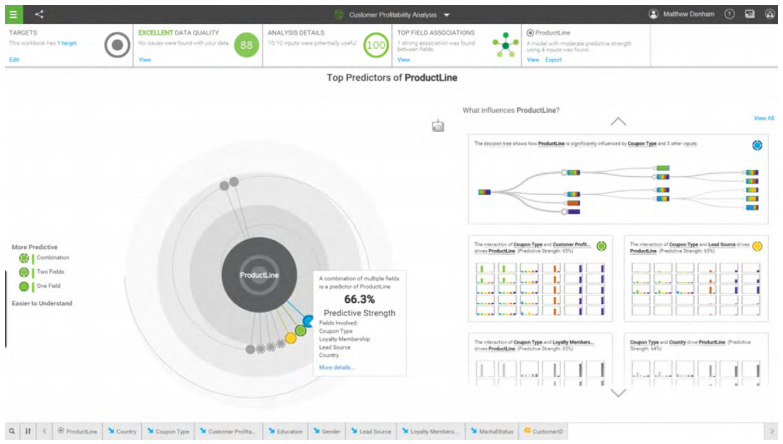
شناسایی عوامل پیشبینی کنندهی رفتار مشتریان با Watson Analytics
ویژگی مهم IBM DataWorks
یکی از قابلیتهای DataWorks استفادهی رایگان این تکنولوژی میباشد. این تکنولوژی فراتر از Bluemix.net قرار گرفته و یک حساب کاربری ایجاد میکند. Bluemix نیز یکی از پیشنهادات IBM برای PaaS بوده و Gateway مناسبی برای طیف وسیعی از سرویسهای داده Cloud به شمار میرود و شامل مواردی می شود که کاملا قابل ادغام با DataWorks میباشد، مانند dashDB Cloud Data Warehouse و سرویس پایگاه داده Cloudnt NoSQL.
با توجه به اینکه استفاده از DataWorks تا حداکثر 1000 ردیف داده، بدون هزینه و رایگان میباشد، بنابراین میتوانید بارگذاری و شکلدهی به دادهها را بدون هرگونه ریسک مالی آغاز نمایید و سپس به سوی گامهای بعدی پیش روید. برای مجموعه دادههای بزرگتر، به اندازه مصرف از این تکنولوژی پول پرداخت میکنید، بنابراین منابع مالی خود را برای زیرساختی که قرار نیست از آن استفاده نمایید، هدر نمیدهید.
IBM Cloud Data Services چیست؟

IBM Cloud Data Services ، یک مجموعهی جامع و کامل از سرویسهای داده یکپارچه و قدرتمند را برای Developerها و کارشناسان داده ارائه مینماید که محتوا، داده و آنالیز را در برمیگیرد. این سرویس، علاوه بر آنکه زمان ورود به بازار را تسریع مینماید، زمان کارکرد سیستم را بهبود بخشیده و سطوح بالاتری را برای برنامه نویسان Web Application و Mobile App ارائه مینماید.
ــــــــــــــــــــــــــــــــــــــــــــــ
مفهوم IBM DataWorks و کاربردهای آن – قسمت اول
