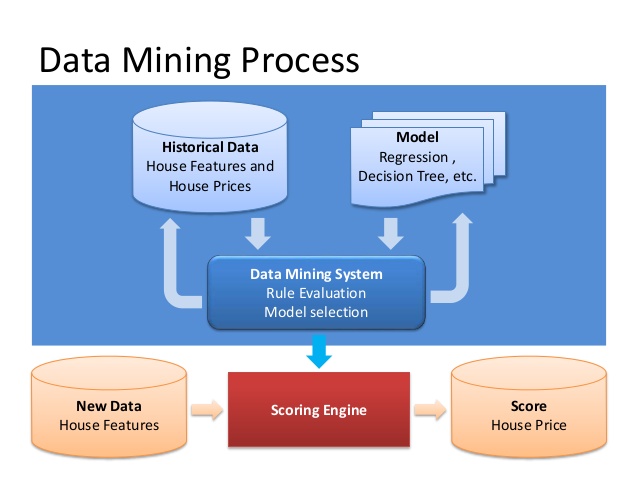
رشد چشمگیر حجم و پیچیدگی دادههای IT در چند سال اخیر موجب شده است تا فرآیندهای مرتبط با دادهکاوی اهمیت بیشتری یابد. با استفاده از مدل دادهکاوی و قابلیتهای آن میتوان آنالیزهای پیشرفتهتری را بر روی دادهها انجام داد و در نتیجه نتایج مطلوبتری را نیز دریافت نمود. در قسمت اول از سری مقالات مدلهای دادهکاوی، به تعریف مدلهای دادهکاوی و بررسی معماری آنها پرداختیم. در این مقاله که قسمت دوم (پایانی) از این سری مقالات میباشد، به بررسی ویژگیهای مدل دادهکاوی میپردازیم.

ویژگیهای مدلهای دادهکاوی
هر یک از مدلهای دادهکاوی دارای ویژگیهایی است که مدل و Metadata مربوط به آن را تعریف میکند. این ویژگیها شامل نام، شرح، تاریخ آخرین پردازش مدل، دسترسیهای مربوط به مدل و تمامی فیلترها برای دادههای مورد استفاده جهت Training میشود.
به علاوه هر یک از مدلهای دادهکاوی دارای مشخصاتی است که از ساختار دادهکاوی ایجاد شده و ستونهای دادهی مورد استفاده در مدل را توصیف میکند. در صورتی که ستونهای مورد استفاده در مدل به صورت Nested Table باشد، میتوان از یک فیلتر مجزای دیگر برای ستون مربوط استفاده نمود. در ضمن، هر یک از مدلهای دادهکاوی شامل دو ویژگی خاص “الگوریتم” و “کاربرد” میباشند.
بیشتر بخوانید: مفهوم و نحوه کارکرد دادهکاوی یا Data Mining – قسمت اول
- ویژگی الگوریتم : با این ویژگی میتوان الگوریتم مورد استفاده برای ایجاد مدل را تعیین نمود. الگوریتم مورد نظر با توجه به Provider انتخاب شده توسط کاربر، قابل دسترس خواهد بود. از این ویژگی در مدل دادهکاوی استفاده شده و برای هر مدل فقط یکبار قابل تنظیم میباشد. لازم به ذکر است که امکان تغییر الگوریتم در مراحل بعدی وجود دارد اما ممکن است به دلیل پشتیبانی نکردن الگوریتم، برخی ستونها حالت Invalid پیدا نمایند. ضمن اینکه کاربران باید مدل مورد نظر را پس از ایجاد هرگونه تغییر در این ویژگی مجددا پردازش نمایند.
- ویژگی کاربرد یا Usage: با این قابلیت میتوان چگونگی استفاده از هر ستون را در مدل تعریف کرد. به علاوه اینکه کاربرد ستونها تحت عنوان Input، Predict، Predict-Only و Key قابل تعریف میباشد. این قابلیت برای هر یک از ستونهای مجزا در مدل دادهکاوی به کار رفته و میبایست برای هر یک از ستونهای مدل به صورت جداگانه تنظیم گردد. درصورتی که یک ستون در ساختار وجود داشته باشد اما در مدل استفاده نگردد، وضعیت کاربردی آن در حالت Ignore قرار میگیرد. برای مثال، ستونهای حاوی نام مشتری و آدرس ایمیل دو نمونه از دادههایی محسوب میشوند که در ساختار دادهکاوی وارد شده اما در فرآیند آنالیز مورد استفاده قرار نمیگیرند. بدین ترتیب امکان ایجاد Query بر روی دادهها بدون نیاز به وارد کردن آنها در روند آنالیز امکانپذیر میگردد.
پس از ارائه مدل دادهکاوی این امکان وجود دارد که میزان ویژگیها در مدل تغییر داده شود. با این وجود هرگونه تغییر حتی در نام مدل دادهکاوی مستلزم پردازش مجدد مدل میباشد. ضمن اینکه با پردازش مجدد مدل ممکن است نتایج متفاوتی به دست آید.
ستونهای مدلهای دادهکاوی
مدلهای دادهکاوی شامل ستونهای داده میباشد که این ستونها از ستونهای تعریفشده در ساختار دادهکاوی ایجاد شدهاند. بنابراین کاربران میتوانند ستون موردنظر خود را از ساختار دادهکاوی جهت استفاده در مدل انتخاب نمایند؛ ضمن اینکه امکان کپیبرداری از ستونهای ساختار دادهکاوی و سپس تغییرنام و یا تغییر کاربری آنها نیز فراهم میگردد. علاوه بر این موارد، تعریف روند کاربرد ستون در مدل باید به عنوان بخشی از فرآیند ساخت آن توسط کاربر تعریف شود. این بخش شامل اطلاعاتی مبنی بر این موارد است که آیا ستون به عنوان یک Key میباشد، برای پیشبینی مورد استفاده قرار گرفته و یا به واسطه الگوریتم نادیده گرفته میشود.
بیشتر بخوانید: آشنایی با الگوریتمهای دادهکاوی یا Data Mining
در هنگام ایجاد مدل توصیه میشود که به جای افزودن ستونها، دادههای ساختار به دقت مورد بررسی قرار گرفته و تنها ستونهایی در مدل وارد شود که هدف خاصی از آنالیز آنها وجود داشته باشد. برای مثال باید از اضافه کردن چندین ستون با دادههای تکراری یا استفاده از ستونها با مقادیر نسبتا منحصربهفرد اجتناب شود. در صورتی که یک ستون مورد استفاده قرار نگیرد، لزومی به حذف آن از ساختار یا مدل دادهکاوی نیست؛ بلکه با قرار دادن یک Flag یا نشانه برروی ستون میتوان آن را از فرآیند تهیه مدل کنار گذاشت. بدین ترتیب، ستون در ساختار دادهکاوی باقی میماند اما در مدل دادهکاوی مورد استفاده قرار نمیگیرد. در صورتی که فرآیند Drill through از مدل تا ساختار دادهکاوی فعال شده باشد، کاربر میتواند در صورت لزوم این اطلاعات را از ستون بازیابی نماید.
برخی از ستونها در ساختار مدلهای دادهکاوی ممکن است بسته به الگوریتمِ مورد استفاده با انواع خاصی از مدلها سازگاری نداشته باشد یا نتایج نامناسبی را ارائه نمایند. برای مثال اگر دادهها شامل دادههای عددی پیوسته مانند اطلاعات مربوط به «درآمد» باشند و مدل به مقادیر عددی گسسته نیاز داشته باشد، کاربر باید دادهها را به مقادیر گسسته تبدیل نماید و یا آنها را از مدل حذف نماید. در برخی موارد، الگوریتم این تبدیل را به صورت خودکار انجام میدهد اما ممکن است نتیجهی آن همیشه مطابق خواسته یا انتظار کاربر نباشد؛ بنابراین توصیه میگردد از ستون مربوطه چند کپی تهیه و با مدلهای مختلف بررسی گردد. همچنین این امکان وجود دارد تا با قرار دادن Flag برروی ستونهای جداگانه نشان داد که پردازش در چه نقاطی ضروری است. برای مثال در صورتیکه اطلاعات شامل دادههای Null باشد میتوان از یک Flag برای کنترل روند استفاده نمود. همچنین در صورتی که یک ستون خاص در مدل به عنوان Regressor در نظر گرفته شود، میتوان این کار را با Flag مدلسازی انجام داد.
پس از ایجاد مدل میتوان تغییراتی مانند حذف یا اضافه نمودن ستونها یا تغییر نام مدل را ایجاد کرد. اما باید توجه داشت که پس از ایجاد تغییرات حتی در Metadataهای مدل، پردازش مجدد مدل ضرورت مییابد.
پردازش مدلهای دادهکاوی
مدل دادهکاوی تا قبل از پردازش فاقد هر گونه اطلاعات میباشد. در هنگام پردازش مدل، دادههای Cache شده از طریق ساختار از فیلتر عبور کرده و در صورتیکه دادهای در مدل تعریف شده باشد، توسط الگوریتم آنالیز میگردد. الگوریتم به محاسبهی مجموعهای از خلاصه اطلاعات آماری میپردازد که قواعد و الگوهای موجود در بین دادهها را شناسایی نموده و سپس این اطلاعات را وارد مدل مینماید.
مدل دادهکاوی پس از انجام پردازش، شامل اطلاعات زیادی در مورد دادهها و الگوهای به دستآمده از آنالیز میشود که اطلاعات آماری، قواعد و فرمولهای رگرسیون را در بردارد. همچنین کاربران میتوانند از Viewerهای سفارشی برای جستجوی این اطلاعات استفاده نموده و یا Queryهای دادهکاوی را برای بازیابی این اطلاعات و استفاده از آنها برای آنالیز و ارائه نتایج ایجاد نمایند.
فرآیند مشاهده و Query نمودن مدلهای دادهکاوی
پس از پردازش مدل میتوان با استفاده از Viewerهای سفارشیِ موجود در SQL Server Data Tools و SQL Server Management Studio به شناسایی مدل پرداخت.
علاوه بر این، میتوان Queryهایی را برای مدل دادهکاوی ایجاد نمود که برای پیشبینی یا بازیابی Metadata یا الگوهای به دست آمده از مدل به کار میرود. همچنین امکان ایجاد Query با استفاده از Data Mining Extensions یا به اختصار DMX فراهم میگردد.
ـــــــــــــــــــــــ
بررسی مدلهای دادهکاوی و سرویسهای آنالیز – قسمت اول
بررسی مدلهای دادهکاوی و سرویسهای آنالیز – قسمت دوم (پایانی)
