
امکان تصویرسازی Hadoop
امروزه چالش پیش رو در زمینهی Big Data نحوه درک آن میباشد و این در حالی است که در گذشته نحوه ذخیرهسازی آن به عنوان چالش اصلی در این زمینه مطرح بوده است. Oracle Big Data Discovery به عنوان یک رویکرد کاملا جدید جهت درک Big Data، سازمانها را برای مشاهده و درک سریع پتانسیل دادههای خام در Hadoop، تبدیل وضعیت دادهها به حالتی بهتر و شناسایی و اشتراک ارزشهای جدید در قالب یک محصول تصویری به صورت واحد، توانمند میسازد. این تکنولوژی با ارائه سرعت فوقالعاده در مقیاسهای بزرگ، میتواند فرآیند آنالیز Big Data جهت ارائه ارزشهای جدید را تسهیل نماید.

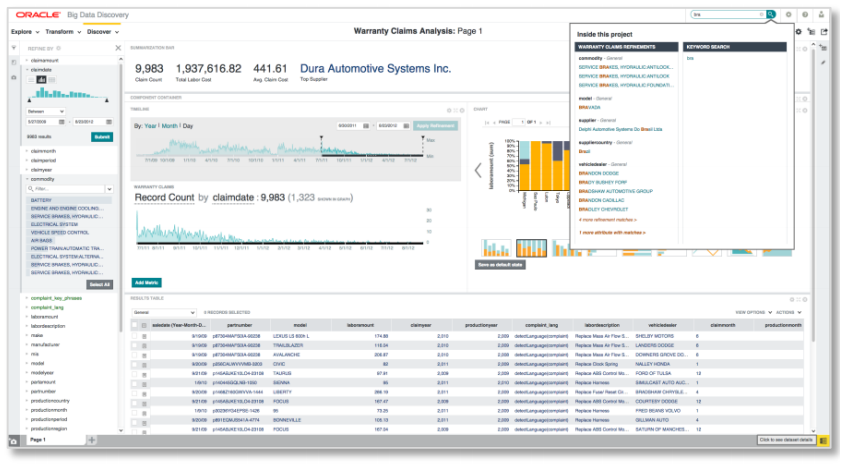
محیط Oracle Big Data Discovery
کشف و یافتن Big Data
با استفاده روزافزون سازمانها از Hadoop برای ذخیرهی حجم زیادی از دادهها که حتی فراتر از انبارهای داده (Warehouse) سازمانها نیز میروند، این تکنولوژی همچنان محبوبیت بیشتری کسب میکند. با توجه به اینکه جمعآوری و ذخیره Big Data به عنوان گام اول برای استفاده از این نوع داده در تجزیه و تحلیل امری ضروری به شمار میرود، برای برخی سازمانها به عنوان تنها گام پیشرو نیز محسوب میشود. رویکردهای موجود برای آنالیز دادهها به راحتی با Big Data همراه نمیشوند، زیرا این دادهها به واسطه ماهیت خود بسیار جدید، ناآشنا و در حال تغییرات مداوم بوده و همچنین از کیفیتهای بسیار متنوعی نیز برخوردار میباشند. بدین ترتیب رویکردهای موجود سازمانها را با گزینههای دشواری روبرو میکند که عبارتند از: بهکارگیری منابع کاملا تخصصی که از ابزارهای پیچیده و غیر یکپارچه برای درک Big Data استفاده مینمایند؛ یا کنار هم قرار دادن یک سری از راهکارها برای دستیابی به تصویری از ماهیت و ارزش دادهها.
با توجه به مطالب بیان شده، بدیهی است که ضرورت وجود یک رویکرد کلی و جامع برای Big Data وجود دارد تا علاوه بر اینکه روشی ساده را با کاربری آسان برای مشاهدهی دادههای جمعآوری شده در Hadoop و درک سریع پتانسیل آن دراختیار سازمانها قرار دهد، بتواند به صورت تصویری (Visual) و پویا و بدون نیاز به ابزار سوئیچینگ نیز با دادهها کار کند و از طریق کشف تعاملی (Interactive Discovery) با دادهها مشارکت نموده و به سرعت به سمت ایجاد قابلیتهای تصویرسازی (Visualization) و اشتراک دیدگاهها با همکاران حرکت نماید تا امکان بهرهمندی هر چه بیشتر سازمانها از استعدادهای تحلیلی و نوآوریها را فراهم نماید.
Oracle Big Data Discovery برای پاسخگویی به این نیازها طراحی شده است؛ این تکنولوژی علاوه بر افزایش قابلیت دسترسی به Big Data برای تمامی افراد حاضر در سازمان، ریسکهای مربوط به پروژههای Big Data را کاهش داده و زمان دستیابی به نتایج ارزشمند را نیز تسریع مینماید.
مشاهده پتانسیل Big Data
توجیه سرمایهگذاری بر روی دادهها بدون مشاهده بازدهی آن، کار دشواری است؛ علاوه بر آن نیز بدون آگاهی از آنچه در دادهها وجود دارد، به سختی میتوان ارزش بالقوه دادهها را برآورد نمود. Oracle Big Data Discovery با ارائه دسترسی سریع تصویری به تمامی دادهها در Hadoop به حل این مشکل پرداخته است، بنابراین سازمانها میتوانند:
- با کمک یک فهرست تعاملی قوی از دادههای خام در Hadoop، سریعا دادههای مرتبط را بیابند.
- دادههای Local را از طریق Wizardهای Self-Service از فایلهای Excel و CSV بارگذاری نمایند.
- خلاصهای از مجموعه دادهها، یادداشتهای سایر کاربران و پیشنهادات ارائه شده در مورد مجموعه دادههای مرتبط را مشاهده نمایند.
- دادهها را از طریق فرآیندهای جستجوی مکرر و جهتیابیهای هدایت شده شناسایی نمایند.
فهرست تعاملی مربوط به Big Data Discovery
این قابلیتها در کنار آمار مربوط به هر یک از این ویژگیهای جداگانه در مجموعه دادهها، میتواند شکل دادهها را نمایش داده، توانایی درک سریعی از کیفیت دادهها را برای کاربران مهیا نموده و علاوه بر شناسایی اختلالات و کشف دادههای خارج از محدوده (Outlier)،در نهایت پتانسیل آنها را نیز تعیین نماید.
در نتیجهی این امر سازمانها میتوانند:
- Attributeها را با توجه به نوع دادهها تصویرسازی نمایند و با نگاهی مختصر دادههای مرتبط را مشاهده کنند.
- Attributeها را به لحاظ پتانسیل دستهبندی نمایند، که در ابتدا معنادارترین اطلاعات نمایش داده شوند.
- از Scratch Pad برای کشف و شناسایی الگوهای بالقوه و همبستگی بین صفتها استفاده نمایند.
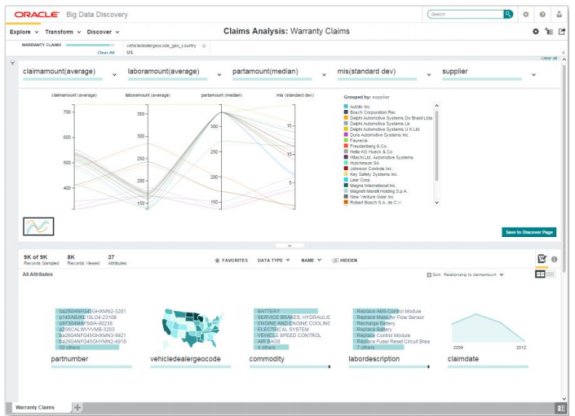
کشف و شناسایی دادهها با Oracle Big Data Discovery
بهینهتر ساختن سریع Big Data با Oracle Big Data Discovery
یکی از چالشهای پیشرو در فرآیند آنالیز دادهها در هر مقیاسی، آن است که این دادهها به ندرت از همان ابتدا آماده استفاده بوده و معمولا مستلزم مقادیر متفاوتی از پاکسازی و تغییر میباشند. همچنین کسب بالاترین ارزش تحلیلی به معنای توسعه بیشتر دادهها، استخراج Themeها و ترکیب نمودن مجموعهای از دادهها با هدف ارائه الگوهای جدید میباشد. در چشمانداز کنونی Big Data، تغییر و غنیسازی غالبا به صورت Upstream و با ابزارهای مختلف کنترل میشود که قابلیت تغییر شرایط را دارد و زمان دستیابی به نتایج کاربردی را افزایش میدهد.

ایجاد تغییر در دادهها با Oracle Big Data Discovery
در این تکنولوژی، تبدیل و غنیسازی دادهها به صورت Native در یک واسط کاربریِ تعاملی و Visual با کاربری ساده ایجاد شده و در پشت پرده از قدرت Apache Spark (که در مقالات قبلی سایت به آن پرداخته شده است) استفاده مینماید تا حجم زیادی از دادهها را در مقیاس تغییر داده و در عین حال عدم از دست رفتن شرایط و ساختار را تضمین نماید. کاربران از کارشناسان داده گرفته تا تحلیلگران کسبوکار میتوانند:
- دادهها را از طریق یک واسط کاربری ساده با سبک Spreadsheet در محلی در Hadoop جمعآوری نماید.
- از مجموعه گستردهای از تغییرات معمول برای داده مانند بخشبندی (Split)، ادغام (Merge)، گروه بندی یا جایگزینی مقادیر و بسیاری موارد دیگر بهره گیرند.
- قابلیت استنباط زبان یا ایجاد سلسله مراتب جغرافیایی از فیلدهای آدرس و استخراج Theme مورد نظر از متن را به صورت خودکار ارائه نمایند.
- تغییرات مربوط به دادههای نمونه را قبل از کاربرد آنها برای مجموعه کاملی از دادهها در Hadoop، آزمایش نمایند.
- یک پیشنمایش (Preview) از نتایج ارائه نموده و تغییرات را قبل از اجرای آنها، Undo نموده یا مجددا ایجاد کنند.
ــــــــــــــــــــــــــــــــــــــــــ
