
در قسمت اول از مقاله Oracle Big Data Discovery به بررسی یافتن Big Data و بهینه سازی آن پرداختیم و در این قسمت به بررسی Big Data Discovery خواهیم پرداخت.

ارائه Big Data Discovery به صورت عمومی
یکی از نکات مهم در رابطه با Big Data Discovery آن است که این محصول به ارائه فرآیند کشف و شناسایی برای تحلیلگران کسبوکار همانند کارشناسان داده میپردازد. با استفاده از این قابلیت، هر یک از اعضای تیم Big Data، زمان کمتری برای آمادهسازی و زمان بیشتری را برای آنالیز صرف خواهد کرد. Big Data Discovery با تسهیل مراحل اولیهی درک، تغییر و غنیسازی Big Data، بهرهمندی از بهترین عملکرد برای مجازیسازی تعاملی و همچنین کشف و شناسایی دادهها، موجب تسریع فرآیندهای آنالیز میگردد.
بنابراین قابلیتهای زیر برای هر یک از اعضای تیم Big Data فراهم میگردد:
- طرح سوالاتی در مورد دادهها و کسب پاسخ آنها به راحتی یک خرید آنلاین با استفاده از جستجوهای کلی و جهتیابیهای هدایت شده
- فرآیند Drag and Drop برای ارائه تصویرسازی (Visualization) تعاملی و قدرتمند و داشبوردهای شناسایی و ترکیب آنها
- گسترش دیدگاه یا تغییر روند بررسی از طریق ترکیب مجموعه دادههای جدید در یک آنالیز و به روزرسانی تصویرسازیها و داشبوردها در لحظه
- ایجاد مجموعهای از Snapshotها که مسائل موجود در رابطه با Big Data را عنوان نموده و امکان شناسایی و کشف گروهی، از طریق اشتراک Galleryها، Bookmarkها و تمامی پروژهها را در تیم فراهم مینماید.
- افزایش دسترسی و ارزش دادهها از طریق انتشار دادههای ترکیبی برای (Hadoop Distributed File System (HDFS ، که در سراسر سازمان قابل استفاده میباشد.
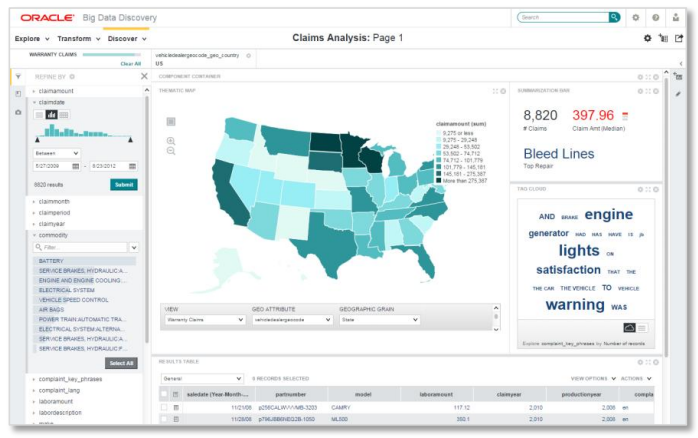
کشف و اشتراکگذاری دیدگاههای جدید با Oracle Big Data Discovery
ایجاد نوآوری فنی در Hadoop با Oracle Big Data Discovery
Oracle Big Data Discovery به ارائه نوآوری فنی در Hadoop پرداخته است، که از قدرت Storage و Computing توزیعی در تمامی سرورها یا Nodeها برای پردازش حجم زیادی از اطلاعات استفاده مینماید، بدون آنکه نیازی به حرکت به سمت آن داشته باشد.
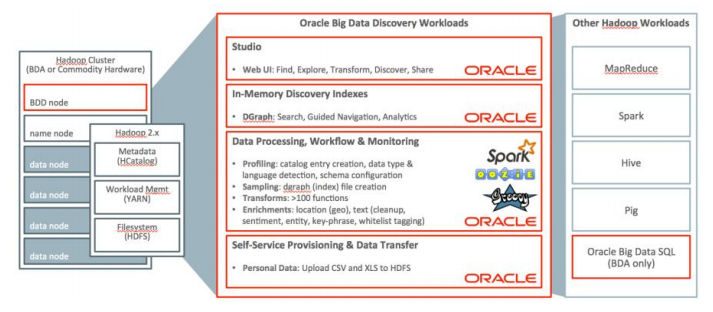
نوآوری فنی در Oracle Big Data Discovery
- Studio، یک واسط کاربری منحصر به فرد و مبتنی بر وب است که روند کشف، شناسایی، تغییر و اشتراک دادهها را برای همه افراد تسهیل مینماید.
- سرور Dgraph، یک پایگاهداده آنالیز-جستجوی ترکیبی است که امکان عملکرد کاربران بر روی مجموعه دادههای In-Memory برای عملکرد تعاملی را فراهم مینماید.
- در پردازش دادهها از Apache Spark برای پروفایلبندی، نمونهگیری، تغییر و غنیسازی حجم زیادی از اطلاعات در سراسر Nodeهای داده در کلاستر Hadoop استفاده میشود.
مدیریت یکپارچه Big Data و راهکارهای آنالیز
Big Data Discovery، یکی از مولفههای مهم در مدیریت کلی Big Data و استراتژیهای تحلیلی به شمار رفته و کاربران را قادر میسازد تا:
- برای آنالیز پیشبینیها از Oracle R Advanced Analytics for Hadoop استفاده نمایند.
- از Oracle Big Data SQL جهت گرفتن Query در مورد دادهها در HDFS بدون جابجا نمودن آن استفاده نمایند.
- راهکارهایی را بر روی سیستمهای مهندسی اوراکل اجرا نموده و پیادهسازی سریع برنامههای کاربردی را میسر سازند که مزایای عملکرد را بهبود بخشیده و هزینه کلی مالکیت را کاهش میدهد.
کشف و شناسایی Big Data
Big Data Discovery به عنوان یکی از اعضای مجموعه Oracle Big Data Analytics به شمار میرود که همراه با راهکارهای دیگر Big Data از اوراکل به ارائه جامعترین پلتفرم Big Data در صنعت میپردازد.
محصولات مرتبط
محصولات تکمیل کننده Oracle Big Data Discovery عبارتند از:
- Oracle Big Data Appliance
- Oracle Big Data SQL
- Oracle R Advanced Analytics for Hadoop
مزایای مهم استفاده از Oracle Big Data Discovery
- درک سریع پتانسیل Big Data و آگاهی از نقطه شروع
- قابلیت پیشبینی و توجیه سرمایهگذاری
- آگاهی سریع در زمانی که کار نباید ادامه یابد.
- تغییر و غنیسازی دادهها در مقیاس بزرگ به منظور بهبود دادهها برای همه افراد
- تلاش 80 درصدی برای آنالیز و ارائه دیدگاه به جای آمادهسازی داده
- گسترش تیمهای Big Data به منظور مشارکت تحلیلگران کسبوکار و ارائه نتایج جمعی و گروهی
- پردازش مناسب دادهها در Hadoop که نتیجه آن همراه با کاهش قابل توجه در جابجایی دادهها و هزینههای مدیریت میباشد.
- پیادهسازی سریع در محیطهای فعلی یا جدید، برای شروع سریع کار
- حذف موانع فنی از طریق یکپارچهسازی با زیرساختهای فعلی و سایر ابزارهای Big Data
- اجرا به صورت یک سیستم مهندسی یا بر روی سختافزار مناسب و توسعه آسان به منظور سازگاری با پیشرفتها
ویژگیهای مهم Big Data Discovery
-
قابلیت یافتن
– دسترسی به یک فهرست غنی و تعاملی از تمامی دادهها در Hadoop
– استفاده از جستجوهای آشنای تکرارشونده و جهتیابیهای هدایت شده برای یافتن سریع اطلاعات
– مشاهده خلاصهای از مجموعه دادهها، یادداشتها و پیشنهادات کاربران
– آمادهسازی دادههای شخصی و سازمانی برای Hadoop به صورت Self-Service
-
شناسایی
– تصویرسازی یا به عبارتی Visualize نمودن تمام ویژگیها بر اساس نوع آنها
– دستهبندی ویژگیها از طریق پتانسیل اطلاعات
– ارزیابی آمار مربوط به ویژگیها، کیفیت داده و دادههای خارج از محدوده (Outlier)
– استفاده از Scratch Pad برای نشان دادن همبستگی بین Attributeها
-
تغییر
– آمادهسازی دادهها برای آنالیز از طریق Data Wrangling
– بهرهمندی از مجموعه گستردهای از تغییرات و غنیسازی دادهها
– پیشنمایش نتایج، Undo کردن و اجرای مجدد تغییرات
– آزمایش دادههای نمونه در حافظه و سپس اعمال آن برای مجموعه دادهها در Hadoop
-
کشف و شناسایی
– ترکیب دادهها برای دستیابی به دیدگاههای دقیقتر
– ارائه صفحات پروژه از طریق Drag and Drop
– استفاده از قابلیت جستجوی قدرتمند و جهتیابیهای هدایت شده برای طرح سوالات
– مشاهده الگوهای جدید در تصویرسازی دادههای تعاملی
-
اشتراکگذاری
– اشتراکگذاری پروژهها، Bookmarkها و Snapshotها با دیگران
– ایجاد گالریها و بیان مسائل مربوط به Big Data
– تعامل و همکاری به عنوان یک تیم
– انتشار دادههای ترکیبی با HDFS جهت بهرهمندی از سایر ابزارها
ــــــــــــــــــــــــــــــــــــــــــ
