دلایل استفاده از قابلیت HA در مجازی سازی سرور VMware چیست؟ در زیرساخت محصولات VMware مفهوم High Availability یک اصل بنیادی است. ویژگی High Availability (HA) در سال ۲۰۰۳ همزمان با vCenter معرفی شد. ویژگی های دیگری مانند vMotion و تکنولوژی Virtual SMP نیز در همان سال معرفی شدند. حال به این توضیحات به ادامه موضوع خواهیم پرداخت. شکل زیر زیرا واکنش محیط ایزوله برای روشن بودن تنظیم شده و واکنش جداسازی Single-Host در دیتاسنتر Frimley را از شبکه توضیح میدهد از این شکل همچنین می توان فهمید VMها همچنان در حال کار کردن هستند.

اگر یک Host جدا شود، Node اولیه ی vSphere HA جداسازی را تشخیص می دهد زیرا دیگر Heartbeat شبکه را از Host دریافت نمی کند. سپس Node اولیه شروع به کنترل Heartbeatها در Datastore میکند. از آنجا که Host جدا است، برای مکانیسم تشخیص ثانویه vSphere HA، تولید Heartbeat میکند. تشخیص Heartbeat Host معتبر، Node اولیه ی vSphere HA را قادر می سازد تا Hostی که جدا از شبکه در حال کار کردن است را مشخص کند. Hostی که تحت تأثیر قرار گرفته میتواند بسته به واکنش محیط ایزوله ی تنظیم شده، ماشین های مجازی را خاموش و روشن نماید و یا از کار بیاندازد. 30 ثانیه بعد از تشخیص جداسازی توسط Host، واکنش محیط ایزوله شروع میشود.
VMware توصیه میکند واکنش محیط ایزوله با الزامات کسب و کار و محدودیت های فیزیکی هماهنگ شود. Leave Powered On، بهترین روش برای تنظیم واکنش محیط ایزوله در اکثر محیطها است. با توجه به افزونگی Built-In در بیشتر طراحی های مدرن، Hostهای ایزوله شده در یک محیط مناسب طراحی شده، کمیاب هستند. در محیط هایی که از پروتکل های Storage مبتنی بر شبکه مانند iSCSI و NFS که در آنها شبکه ها یکپارچه هستند، استفاده میکنند، واکنش توصیه شده توسط محیط ایزوله، خاموشی است. به احتمال زیاد، در این محیطها قطع شدن شبکه ای که باعث جدایی Host میشود، بر توانایی Host در برقراری ارتباط با Datastoreها نیز تأثیر میگذارد.
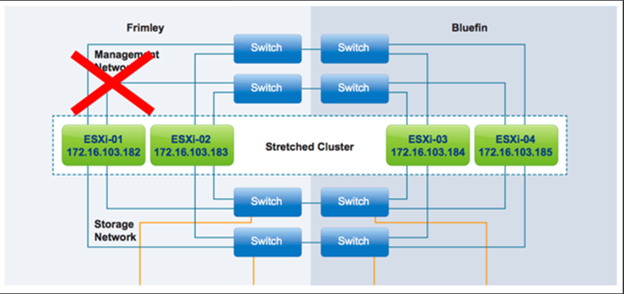
اگر واکنش محیط ایزوله متفاوت از پیشنهاد Leave Power On انتخاب شود و واکنش Power Off و Shut Down فعال شود، vSphere HA ابتدا ماشین های مجازی را روی Nodeهای باقیمانده در کلاستر، مجدداً راه اندازی میکند. قوانین Affinity vSphere VM-To-Host که در سطح کلاستر تعریف شدهاند اجباری هستند. با این حال، از آنجا که vSphere HA به قوانین VM-To-Host Affinity پایبند است، همه ی VMها در شرایط عادی در سایت درست، مجدداً راه اندازی میشوند.
منظور از Storage Partition در قابلیت HA در مجازی سازی سرور VMware چیست؟
همانطور که در شکل زیر نشان داده شده، در این سناریو، خرابی در شبکه ی Storage بین دیتاسنترها رخ داده و VMها بدون هیچ تأثیری در حال کار هستند.
Storage Site Affinity برای هر LUN تعریف شده است و قوانین vSphere DRS با این Affinity همسو هستند. بنابراین، از آنجا که Storage در سایت موجود است، هیچ VMی تحت تأثیر قرار نمیگیرد.
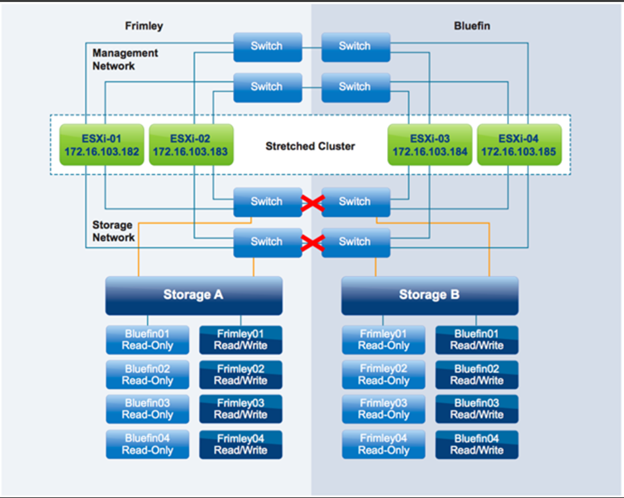
اگر به هر دلیلی Affinity Rule برای یک VM نقض شود و VM در حال اجرا بر روی یک Host در دیتاسنتر Frimley باشد در حالی که دیسک آن در یک Datastore با دیتاسنتر Bluefin مرتبط باشد، نمیتواند با موفقیت I / Oی را که Inter-Site Storage را دنبال میکنند، انجام دهد. دلیل این امر آنست که Datastore در شرایط APD قرار دارد. در این سناریو، میتوان VM را مجدداً راه اندازی کرد زیرا vSphere HA برای پاسخگویی به شرایط APD تنظیم شده است. پاسخ پس از سپری شدن مهلت 3 دقیقه ای رخ می دهد. این مدت زمان 3 دقیقه ای پس از گذشت 140 ثانیه از زمان APD و اعلام وضعیت APD آغاز می شود.
قابلیت HA در مجازی سازی سرور VMware چیست؟ ممکن است مشخص شود که هنگام برداشتن APD قبل از سپری شدن مهلت 3 دقیقه ای، قرار است چه اتفاقی بیفتد. مثلا، یکی از گزینه ها تنظیم مجدد VM است. اگر تنظیم مجدد VM پیکربندی شده باشد، پس از برداشته شدن APD، VM تنظیم مجدد خواهد شد. در این حالت هرگونه دستور راها ندازی مجدد اثر نخواهد داشت. Restart Order و Dependency فقط در مورد ماشین های مجازی است که مجدداً راه اندازی میشوند.
برای جلوگیری از Downtime غیر ضروری در سناریوی APD ،VMware توصیه میکند که بر رعایت قوانین DRS vSphere نظارت شود. اگرچه vSphere DRS هر 5 دقیقه Invoke میشود، اما این امر تضمین کنندهی حل و فصل کلیه موارد نقض Affinity Rule نیست. بنابراین، برای جلوگیری از Downtime غیر ضروری، مانیتورینگ دقیق توصیه میشود که شناسایی سریع ناهنجاری هایی مانند محاسبات VMی که در یک سایت قرار دارد ولی Storage آن در سایت دیگر است را ممکن می سازد.
بخش بندی دیتاسنتر در قابلیت HA در مجازی سازی سرور VMware
در این سناریو ، همانطور که در شکل زیر نشان داده شده دیتاسنتر Firmly، از دیتاسنتر Bluefin جدا شده و همچنین VMها بدون هیچگونه تأثیر پذیریی به کار ادامه میدهند.
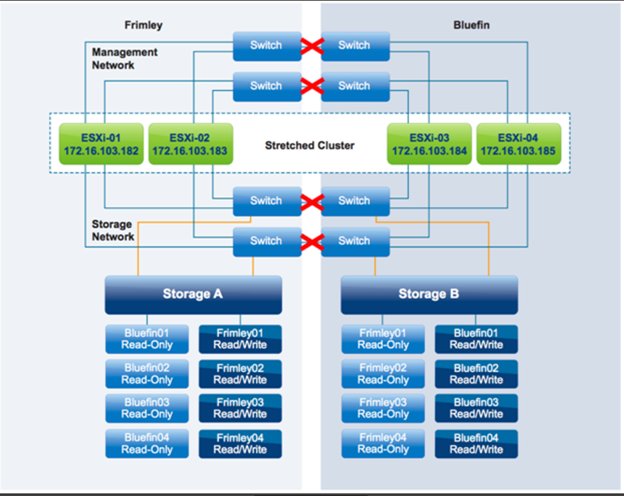
در این سناریو، دو دیتاسنتر کاملاً از یکدیگر جدا شده اند. این سناریو مشابه Storage Partition و سناریوی Host Isolation است. VMها تحت تأثیر این خرابی قرار نمیگیرند زیرا قوانین vSphere DRS به درستی اجرا شده و هیچ قانونی نقض نشده است.
vSphere HA این فرایند منطقی را دنبال میکند تا تعیین نماید کدام ماشین های مجازی در طول یک Cluster Partition نیاز به راه اندازی مجدد دارند:
Node اولیه ی vSphere HA که در دیتاسنتر Frimley اجرا میشود، غیرقابل دسترسی بودن همه ی Hostهای دیتاسنتر Bluefin را مشخص میکند. ابتدا تشخیص میدهد که Heartbeat شبکه دریافت نمی شود. سپس تعیین میکند که آیاHeartbeat ی در Storage ایجاد می شود یا خیر. این بررسی Storage Heartbeat را تشخیص نمی دهد زیرا اتصال Storage بین سایت ها نیز از کار افتاده است و Heartbeat Datastoreها به صورت Locall بروز میشوند. از آنجا که ماشین های مجازی وابسته به Hostهای باقیمانده هنوز در حال کار هستند، هیچ اقدامی برای آنها لازم نیست. در مرحله بعد، vSphere HA امکان شروع دوباره را تعیین میکند. از آنجاییکه، نسخه ی Read/Write مربوط Datastoreها واقع در دیتاسنتر Bluefin توسط Hostها در دیتاسنتر Frimley قابل دسترسی نیست. بنابراین، هیچ تلاشی برای شروع کار VMهای از دست رفته صورت نمیگیرد.
بیشتر بخوانید: بررسی و معرفی قابلیت جدید vSphere پس از انتشار ESXi hypervisor
به همین نحو، Host vSphereها در دیتاسنتر Bluefin تشخیص میدهند که هیچ مورد اولیه ای در دسترس نیست و فرآیند انتخاب اولیه را آغاز میکنند. پس از انتخاب اولیه، تلاش میشود تا مشخص گردد کدام ماشین های مجازی قبل از خرابی در حال کار بوده اند و سعی در راه اندازی مجدد آنها میشود. از آنجا که تمام VMهای دارای Affinity با دیتاسنتر Bluefin هنوز در آنجا کار میکنند، نیازی به راه اندازی مجدد نیست. فقط ماشین های مجازی دارای Affinity به دیتاسنتر Frimley در دسترس نیستند و vSphere HA نمیتواند آنها را مجدداً راهاندازی کند زیرا Datastoreهایی که در آنها ذخیره میشوند با دیتاسنتر Frimley ارتباط دارند و در دیتاسنتر Bluefin در دسترس نیستند.
اگر قوانین VM-To-Host Affinity به Host نقض شده باشد، یعنی ماشین های مجازی در محلی اجرا میشوند که فضای Storage آنها به طور پیش فرض به عنوان Read/Write تعریف نشده باشد، در نتیجه رفتار تغییر میکند. در ادامه توضیح داده میشود که در این صورت چه اتفاقی خواهد افتاد:
1. ماشین مجازی که به دیتاسنتر Frimley وابسته است اما در دیتاسنتر Bluefin قرار دارد، قادر به دستیابی به Datastore خود نیست. این امر منجر به عدم توانایی VMها در نوشتن روی دیسک یا خواندن از روی دیسک میشود.
2. در دیتاسنتر Frimley، این VM توسط vSphere HA ری استارت میشود زیرا Hostهای دیتاسنتر Frimley عملکرد Instance را در دیتاسنتر Bluefin تشخیص نمیدهند.
3. از آنجاییکه Datastore فقط برای دیتاسنتر Frimley در دسترس است، یکی از Hostها در دیتاسنتر Frimley قفل VMDK را پیدا میکند و میتواند VM مورد نظر را روشن کند.
4- این امر میتواند منجر به ایجاد یک سناریو شود که در آن یک VM در هر دو دیتاسنتر روشن و اجرا میشود.
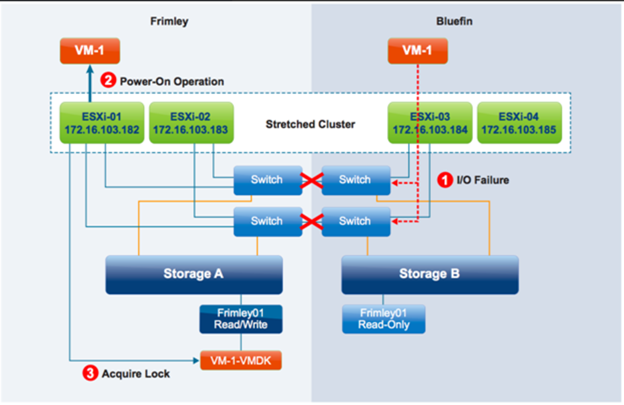
5- اگر واکنش APD به Power Off and Restart VMs (Aggressive)تنظیم شده باشد، پس از ایست APD و به پایان رسیدن مهلت، ماشین مجازی خاموش میشود. این رفتار در vSphere 6.0 جدید است. اگر واکنش APD به درستی تنظیم نشده باشد، دو ماشین مجازی به دلایل احتمالی زیر به کار خواهند افتاد:
Heartbeat شبکه از Hostی که این VM را اجرا میکند، از بین رفته باشد زیرا هیچ ارتباطی با آن سایت وجود ندارد.
Heartbeat Datastore از بین رفته باشد زیرا هیچ ارتباطی با آن سایت وجود ندارد. Ping ارسالی بهManagement Address مربوط به Host که VM را اجرا میکند از کار افتاده باشد زیرا هیچ ارتباطی با آن سایت وجود ندارد.
Primary موجود در دیتاسنتر Frimley تشخیص میدهد که ماشین مجازی قبل از خرابی روشن شده است. از آنجا که پس از خرابی قادر به برقراری ارتباط با Host متعلق به VM در دیتاسنتر Bluefin نیست، سعی در راه اندازی مجدد ماشین مجازی دارد زیرا قادر به شناسایی وضعیت واقعی نیست.
اگر ارتباط بین سایت ها بازیابی شود، سناریوی VM Split-Brain بوجود خواهد آمد. برای مدت زمان کوتاهی، دو نسخه از ماشین مجازی در شبکه فعال خواهند شد که هر دو دارای آدرس MAC یکسان هستند. با این حال، فقط یک نسخه به فایل های VM دسترسی دارد و vSphere HA این را تشخیص میدهد. به محض کشف این موضوع، کلیه ی فرآیندهای متعلق به کپی VM که دسترسی به فایل های VM ندارند، متوقف میشوند، همانطور که در شکل زیر نشان داده شده است.
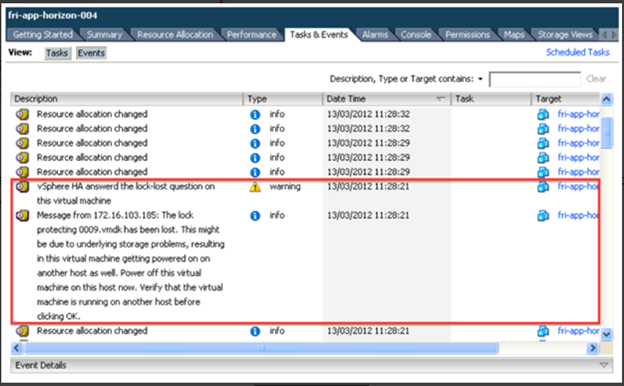
در این مثال، زمان Downtime مصادف با راه اندازی VM است، نگهداری مناسب Affinity سایت میتواند از این امر جلوگیری کند. برای جلوگیری از Downtime غیر ضروری، VMware نظارت دقیق را برای اطمینان از هم خوانی قوانین vSphere HA وCluster DRS با Datastore Site Affinity توصیه می کند.
خرابی Disk Shelf در دیتاسنتر Frimley
در این سناریو، یکی از Disk Shelfها در دیتاسنتر Frimley از کار افتاده است. در این حالت هم Frimley01 و Frimley02 در Storage A تحت تأثیر قرار میگیرند.
