سومين بهروزرسانی در vSphere 7 آخرين نسخه از vSphere 7 را ارائه می دهد كه اين نسخه بهترين معرفی قابليتهای جديد vSphere بوده كه تابهحال وجود داشته است. هر بار كه vSphere به روز ميشود، تغييرات و اصلاحات زيادی در آن صورت می گيرد تا قابليتهايی به آن افزوده گردد، مسائلی رفع شوند، تجربه كاربری بهتر شود و تطبيقپذيری نيز افزايش يابد.

یکپارچه سازی vSphere با Kubernetes
یکی از مطرحترين قابليتهای جديد vSphere اين است كه با Kubernetes يكپارچه شده است كه اين تركيب vSphere با Tanzu ناميده می شود. این قابليت به سازمانها امكان میدهد تا به راحتی برنامههای کاربردی مدرن مبتنی بر Container را در زیرساختهای موجود خود اجرا و پشتیبانی کنند.
یکی از بهترین ويژگيهای vSphere با Tanzu این است که با محیطهای موجود متناسب است. برای اين كه اين نرمافزار با شبكههای بيشتری تطبيق يابد، پشتیبانی منعطف DHCP به آن اضافه شده است. با انتخاب اين قابليت میتوان آدرسهای IP ، DNS ،NTP و سایر مقادیر را به طور خودکار مستقر نمود و در صورت تمایل آنها را لغو كرد. با اين كار، پیکربندی و اجرای آن بسيار سادهتر میشود.
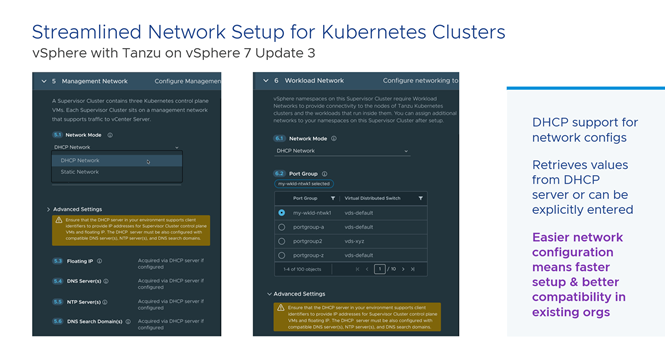
همچنين اين كار هم بهنفع Management Network و هم Workload Network می باشد، اين قابليت همچنين حالت صفر و صدی ندارد و كاربر میتواند Management Network روی حالت استفاده از مقادير Static و Workload Network را روی حالت استفاده از مقادير DHCP تنظيم كند.
راهکار Kubernetes چیست و چه مزایایی دارد
ویدیوهای بیشتر درباره Kubernetes
در اين صورت به كاربر توصيه می شود از شناسههای كلاينت DHCP با DHCP Reservations استفاده كند، كاربر شناسههای كلاينت را در Tanzu پیکربندی میکند و از آنها در سرور DHCP استفاده میکند تا آدرسها حتی در صورت تغییر آدرسهای MAC در ماشينهای مجازی كلاستر بی تغيير بماند. رويداد ممكن است در هنگام ارتقا و زمانی رخ دهد كه VMهای جديدی در كلاستر پيادهسازی می شوند تا جايگزين VMهای سطح پايين شوند.

قسمتهای متحرک زیادی در محیط Kubernetes وجود دارد، و با اين كه بهطور خودكار از بسياری از اين پيچيدگی ها محافظت می شود، بعضا به افرادی نياز است كه اطلاعات اعتباری يا آدرسها را وارد كنند. بنابراین، مشاهده پیام خطای توصیفی مهمتر است. پيامهاي خطا در سومين بهروزرساني بهتر اطلاعرسانی می كنند و در نتيجه كاربر می تواند بهجای آن كه در Logها دنبال خرابی بگردد، سريعا پيكربندی اشتباه را بيابد. به عنوان مثال، در تصویر بالا مشاهده می شود که خطا در پيكربندی تعديلكننده بار باعث شده از نام كاربری اشتباهی استفاده كند.

چرخه عمر، ارتقاء و رفع نقص Patching
از گذشته تا كنون، از کارتهای SD یا دستگاههای USB برای آزادسازی Device Bay و کاهش هزینه نصب میزبان ESXi استفاده شده است. با این حال، چنین دستگاههایی استقامت و اطمينانپذيری كمتر و مشكلاتی را در طول زمان نشان دادهاند. کارتهای SD و درایوهای USB نیز مشکلات عملکردی دارند و ممکن است نتوانند از پس عمليات Read-Write با فركانس بالا برآيند. مشكل نه از فلش، بلكه از طراحی است، زيرا طراحی فلش با ذخيرهسازهاي ديگر متفاوت است. حافظه فلش NAND یک بخش مصرفی است، كه افراد متوجه آن نمی شوند. ولتاژ مورد نیاز برای Write كردن بیتها بهصورت دائمی بر حافظه، با گذشت زمان آن را فرسوده می كند، در طول زمان، اين فرسودگيها جمع می شوند و اگر كاربر به Write كردن بر همان نقطه ادامه دهد، بهطور كامل آن را از بين خواهد برد. اين مثل زمانی است كه بر اثر راه رفتن زياد سوراخی در كفش ايجاد شود.
بیشتر بخوانید: معرفی و نحوه عملکرد Kubernetes در vSphere به همراه بررسی مزایای این تکنولوژی
فلشهايی که برای ورودی/خروجی ببيشتر طراحی شده اند، روشهایی برای مقابله با این نوع سایش دارند تا دستگاه قابل اتكا باقی بماند. درایو SSD یا NVMe در سرور كاربر از روشهای Wear leveling و یا سطح بندی سایش استفاده می كند تا Writeها را در کل درایو پخش كند. این نوع درایوها همچنین دارای ظرفیت اضافی هستند، بنابراین اگر یک واحد از حافظه فرسوده شود، درايو میتواند بدون آن كه كاربر حتی متوجه شود، بهطور يكپارچه جايگزين كند. در حقیقت، اکثر فلشها دارای ظرفیت اضافی قابلتوجهی برای این کار هستند. براي مثال، یک درایو SSD Intel S3500 با ظرفیت 480 گیگابایت در واقع دارای 528 گیگابایت حافظه داخلی است. به همین دلیل است که میزان Storage فلش در Drive Writes Per Day یا DWPD رتبهبندی شده است تا بتواند Workload را با Storage فلش مطابقت دهد. انواع مختلف Storageهای فلش ظرفيت Writing متفاوتی نيز دارند و كاربر بر اساس ميزان استقامتی كه هر درايو دارد، عباراتی نظير Read-Intensive يا Write-Intensive را مشاهده خواهد كرد. به ترتيب فلش Single-level Cell يا SLC، بعد فلش Multi-level Cell d يا MLC و سپس فلش Triple-level Cell يا TLC بيشترين ظرفيت Writing را دارند، سپس سلول چند سطحی MLC و اگر كاربر ظرفيت اين دستگاههاي Storage را برای ميزان Writing موردنظر بهدرستی اندازه بگيرد، تا سالها از آنها سرويس خواهد گرفت.
منسوخ کردن Boot Volumeها درجهت افزایش قابليتهای جديد vSphere
کارتهای SD و فلش مموری ها اما چنين منطق فانتزی ای ندارند. اين دستگاهها ساده هستند و برای سیستمعاملهای مدرن طراحی نشدهاند. حتی دوربین هایی که از کارت های SD استفاده می کنند ، آنها را Mirror میکنند، كه اين پيامی برای كاربر خواهد داشت. همکاران vSphere در حوزۀ سختافزار، تا مدتها از دستگاههای Mirroring برای کارتهای SD استفاده می كردند و كاربران آنها مجبورند كارتها را در طول استفاده از هر سرور چند بار عوض كنند، پس موازنهای اينجا صورت می گرفت.
حال vSphere چه كاری انجام داده است؟ استفاده از درایوهای SD و USB بهعنوان واسطههای Boot را منسوخ كرده است. در قابليتهای جديد vSphere این هشدار را به کاربران میدهد که Boot Volume در حالت تنزلیافته قرار گرفته است، چرا که در حال حاضر مشغول کار بر Back End است تا حجم Writeها بر دستگاه را کاهش دهد.

vSphere Lifecycle Manager همچنان تمام Patching و پیادهسازی را از همه لحاظ به عهده دارد. vSphere اولا ویرایش دپو را به آن اضافه کرده است، زیرا هرازگاهی کاربر نیاز دارد چیزی را هم حذف کند. چنین رویداد ممکن است در زمان نیاز به Driver یا قطعهای دیگر رخ دهد. در این صورت یک Notification برای کاربر ارسال میشود و سپس او میتواند اقدام کند.
بیشتر بخوانید: معرفی VMware vSphere با 101 Kubernetes، بررسی اهداف و قابلیت های آن
ثانیا، تطبیقپذیری سختافزاری دیگر محدود به کنترلکنندههای ورودی/خروجی نیست و Firmware درایو را نیز در بر میگیرد. این گسترش تطبیقپذیری برای vSAN بسیار مهم است، زیرا سفتافزار درایو می تواند تفاوت فاحشی ایجاد کند. باید به خاطر داشت که حتی سخت افزار نیز در حقیقت نرم افزار است و نیاز به Patch شدن دارد. شرکت VMware برای افزودن قابليتهای جديد vSphere همچنان مشغول افزودن همکاران خود به فهرست Vendorهایی است که مدیران پشتیبانی سختافزار آنها میتوانند با Lifecycle Manager کار کنند، بنابراین کاربران خواهند توانست سختافزار و نرمافزار را با هم Patch نموده و همچنین اعلانی ایجاد کنند که مواردی مانند نسخه BIOS را مشخص کند.
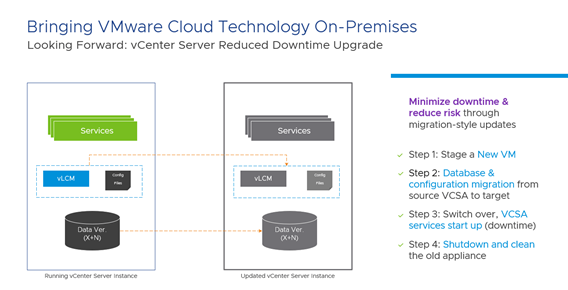
شرکت VMware همواره مشتاقانه میکوشد تا بر عملیات تاثیر مثبت بگذارد. این شرکت اخیراً بسیار به Edge میاندیشد و بهدنبال یافتن راهکارهایی برای برآوردن نیازهای منحصر به فرد آن فضا و نیز راهکارهایی برای کاهش خطرات مرتبط با ارتقا و رفع نقص است. در راستای اين هدف، اين شركت دارد برخی از تكنولوژی ها را – مانند Reduced Downtime Upgrades از VMware Cloud به پيادهسازی های On-premise انتقال می دهد.
اگر كاربر تابهحال vCenter را ارتقا داده باشد، چنين رويدادي برایتان آشنا خواهد بود؛ تفاوت اين است كه اين رويداد ديگر صرفا مختص ارتقاهای اصلی نيست و Patching عادی را نيز شامل می شود. در حال حاضر این برنامه APIمحور است و فعلاً کاربرد رسمی ندارد، با این حال باید به این فکر کرد که چگونه چنین چیزی میتواند در آینده بر محیط کاربر تأثیر بگذارد. قابلیتهای دانلود َAppliance و منابع کافی برای پیادهسازی دومین vCenter Server Appliance یا VCSA اضافه خواهد شد. VCSA جدید همچنین موارد بدی را که برای VCSA پیش آمده لغو میکند، اما قطعا تاییدی بر این Policy است که قسمتهای داخلی Appliance جزئی از محصول است و جز برای عیبیابی نباید آنها را دستکاری کرد. همچنین به هر حال جایگزینی برای پیکربندی Backup از vCenter Server نمی باشد این موارد هنوز بسیار مهم هستند.
