VMware Site Recovery Manager یا SRM تداوم کسبوکار و حفاظت Disaster Recovery را برای محیطهای مجازی VMware به ارمغان میآورد. حفاظت دامنه وسیعی داشته و از ماشینهای مجازی موجود در یک Datastore واحد و همسانسازی شده تا تمامی ماشینهای مجازی موجود در دیتاسنتر را در بر میگیرد و حفاظت سیستمها و برنامههای کاربردی عملیاتی فعال در ماشین مجازی را شامل میشود.

در این مقاله در مورد فراهم کردن پیشنهادات و دادههای عملیاتی SRM بحث شده تا بتوانیم یک پروژه بازیابی موثر را طراحی کرده تا زمان بازیابی را برای محیط ما به حداقل برساند.
ابعاد مختلفی که زمان بازیابی به آن بستگی دارد به شرح زیر است:
- تعداد ماشینهای مجازی و گروههای حفاظتی مربوط به پروژه بازیابی
- ارتقاعات عملکرد بازیابی چندین گروه حفاظتی درون یک پروژه بازیابی
- بهرهگیری از DPM و DRS برای بازیابی بهتر
- تنظیم چندین پارامتر پروژه بازیابی
- تعیین الویت ماشینهای مجازی در پروژه بازیابی
همچنین ما Best Practiceهای حوزههای کاربردی را پیشنهاد میکنیم تا بتوان با استفاده از SRM زمان بازیابی را بهینهسازی نمود.
Site Recovery Manager چیست؟
SRM نیازمند یک سایت حفاظت شده، یک سایت بازیابی و یک سرور SRM است که باید در هر سایت نصب گردد. به علاوه، هر سایت باید توسط vCenter Server خود مدیریت شود. در سایت حفاظت شده، ما یک گروه حفاظتی را ایجاد میکنیم که درواقع یک گروه از ماشینهای مجازی است که باهم Failover میشوند. در سایت بازیابی، ما گروه حفاظتی را اضافه میکنیم که مجموعهای از ماشینهای مجازی است که بصورت همزمان بازیابی میگردند.
ویدیوهای بیشتر درباره SRM
SRM از ذخیرهسازهای vVol ،vSAN ،NFS ،iSCSI ،FC و Local و سه حالت همسانسازی پشتیبانی میکند: همسانسازی مبتنی بر Array یا ABR که در آن Subsystem ذخیرهساز همسانسازی ماشین مجازی را مدیریت میکند، همسانسازی vVol (با استفاده از همسانسازی مبتنی بر Array) و همسانسازی مبتنی بر Host (همسانسازی vSphere) که در آن ESXi همسانسازی ماشین مجازی را مدیریت میکند. SRM بطور خودکار تنظیمات Datastoreها را برای همسانسازی مبتنی بر Array میان سایتهای حفاظتی و بازیابی شناسایی میکند.
جهت مشاوره رایگان و یا راه اندازی زیرساخت مجازی سازی دیتاسنتر با کارشناسان شرکت APK تماس بگیرید. |
vSphere Replication یا VR تنها آخرین دادههای حوزههای تغییر یافته Disk را همسانسازی میکند تا بهرهوری شبکه را افزایش داده و الزامات ABR لازم برای داشتن Arrayهای ذخیرهساز مشابه را در تمامی سایتها برطرف نماید. SRM از 2000 ماشین مجازی برای VR پشتیبانی میکند.
ملاحظات عملکردی در طراحی یک پروژه Disaster Recovery
Recovery Point Objective یا RPO و Recovery Time Objective یا RTO دو مورد از مهمترین معیارهای عملکرد هستند که باید هنگام طراحی و اجرای یک پروژه Disaster Recovery در خاطر داشت.
- RPO زمانهایی را مشخص میکند که در آنها دادهها باید به منظور عمل به توافقات بازیابی شوند.
- RTO مدت زمانی است که طی آن فرآیند کسبوکار باید پس از یک Disaster یا اختلال بازیابی شود تا از عواقب مربوط به خلل تداوم کسبوکار خودداری شود.
برای همسانسازیهای مبتنی بر Array ،RPO توسط برنامهریزیهای تنظیم شده همسانسازی در ذخیرهساز Array برطرف میگردد برای همسانسازی vSphere، با استفاده از پلاگین SRM در vSphere Client تنظیمات RPO را انجام میدهیم. حداقل RPO قابل تنظیم برای VR برابر است با 15 دقیقه. الگوریتم VR بطور پویا برنامهریزی همسانسازی را تنظیم میکند تا نیازهای RPO برطرف گردد. Site Recovery Manager به ما کمک میکند تا با به حداقل رساندن زمان بازیابی دیتاسنتر RTO را تامین کنیم که برای تداوم هر کسبوکار و راهکار Disaster Recovery ضروری و حیاتی است.
بیشتر بخوانید: بررسی Replication در SRM و vVols
طراحی پروژه بازیابی
این قسمت Best Practiceهای Site Recovery Manager را در حوضههای مختلف بیان میکند. این Best Practiceها به ما کمک میکنند تا پروژههای بازیابی سودمندی را طراحی کنیم که زمان بازیابی را به حداقل برسانند.
ارتباط ماشین مجازی با گروه محافظت
با ABR و برای هرگروه محافظت در یک پروژه بازیابی، Site Recovery Manager نیازمند ارتباط با ذخیرهساز اصلی است تا Snapshotهای LUNها را در آن گروه حفاظتی ایجاد کند و یا LUNهای همسانسازی شده و آنها را به Hostهای سایت بازیابی Preset نماید.
زمان بازیابی – iSCSI/FC در مقایسه با NFS
به هنگام کار کردن با ذخیرهساز NFS، SRM طی بازیابی، Snapshotها/Volumeهای همسانسازی شده را در Hostهای ESXi قرار میدهد، این بدان معناست که اگر قرار دادن یک NFS Volume همسانسازی شده در یک Host واحد سایت بازیابی X ثانیه طول میکشد و ما دارای چندین Volume برای قرار دادن در چندین Host در کلاستر سایت بازیابی هستیم، پس تقریبا ((Volumeهای ویژه که باید در تمامی Hostها قرار گیرند)/(2) * Xثانیه) طول میکشد تا در طی یک بازیابی، تمامی Volumeها در تمامی Hostها قرار گیرند و این برای برای هردو بازیابیهای واقعی و آزمایشی صدق می کند همچنین رفتار مشابهی برای Volumeهای قرار نگرفته انتظار میرود.
برای بازیابیهای در مقیاس بزرگتر با تعداد Hostها و NFS Volumeهای بیشتری که ماشینهای مجازی حفاظتشده را Host میکنند، ممکن است زمان بیشتری برای قراردادن یا ندادن NFS Volumeها در تمامی Hostهای سایت بازیابی نسبت به اسکنکردن دوباره تمامی Host HBAها برای iSCSI/FC نیاز باشد.
به هنگام کار کردن با ذخیرهساز iSCSI/FC، SRM یک اسکن مجدد را در HBAهای Host که برای بازیابی استفاده شده، آغاز میکنند تا ذخیرهساز را برای تمامی میزبانان در طی بازیابی، قابل دسترس نمایند، این درخواستهای اسکن مجدد بطور موازی در تمامی Hostهای سایت بازیابی صادر میگردند.
نکته قابل نتیجه گیری این است که داشتن NFS Volumeهای کمتر اما بزرگتر موثر است، زیرا زمان قرار دادن تعداد بسیاری از چنین Volumeهایی در طی بازیابی کاهش مییابد. این امر ممکن است به معنی گروههای حفاظتی کمتر در تنظیمات باشد.
استقرار ماشین مجازی Placeholder
زمانی که برای مجموعهای از ماشینهای مجازی موجود در سایت حفاظت شده یک گروه حفاظتی ایجاد میکنیم، SRM ماشینهای مجازی Placeholder را در هر سایت بازیابی برای هر ماشین مجازی میسازد. در طی بازیابی، SRM هر یک از این ماشینهای مجازی Placeholder را با نسخه کامل ماشینهای مجازی جایگزین میکند که از Datastore بازیابی شدهاند. SRM بطور خودکار از DRS مستقل از هرگونه تنظیمات کلاستر/DRS بهره میگیرد تا بطور بهینه ماشینهای مجازی را در تمامی ESXi Hostهای مختلف در کلاستر قرار دهد و حتی از Hostهایی که به تازگی اضافهشدهاند نیز استفاده می کند. این امر اطمینان میدهد که کلاسترهای ما پس از پایان بازیابی در تعادل بوده و همچنین در حین Boot Storm به عملکرد ماشین مجازی و کلاستر زمانی که بسیاری از ماشینهای مجازی پس از بازیابی بطور همزمان روشن میشوند کمک می کند. SRM دو قابلیت بازیابی ماشین مجازی را در هر Host شروع کرده میتواند همزمان تا 18 عملیات را در طی بازیابی آغاز نماید. اکنون SRM بطور پیشفرض تعداد نامحدودی از عملیات را در تمامی Hostها شروع و این امر بطور چشمگیری در کاهش زمان بازیابی موثر است.
بیشتر بخوانید: بررسی قابلیت پشتیبانی VMware VVols از SRM
SRM همچنین قابلیت خود ترمیمی یا Resiliency خطای Host را هم ارائه میدهد اگر یک سرور ESXi که یک ماشین مجازی Placeholder را Host میکند در طی بازیابی پاسخ ندهد مثلا، اگر Host ESXi به Datastore بازیابی شده دسترسی ندارد، SRM سایر Hostهای قابل دسترسی را انتخاب میکند.
- به عنوان نتیجه گیری می توان گفت داشتن vSphere DRS فعال در سایت بازیابی اقدام موثری است. SRM 5.0 از DRS بهره میگیرد تا منابع کافی را در طی بازیابی در دسترس نگه دارد و با موفقیت تمامی ماشینهای مجازی را روشن نماید.
پیکربندی پارامترهای Job Throttling برای عملیات ماشین مجازی
SRM پارامترهای خاصی را برای کنترل کردن عملیات Boot و Shutdown در هر کلاستر و Host ارائه میدهد. ممکن است بخواهیم این پارامترها را به میزان مطلوبی که با قابلیتهای سیستمهای زیرساختی که برای Disaster Recovery استفاده میگردند تنظیم کنیم، این امر به ما کنترل Boot Storm اجراشده از سوی بازیابی SRM-Initiated را میدهد.
در اینجا دادههایی وجود دارند که میزان تاخیر Guest Boot Up اضافه شده به کل زمان بازیابی را مشخص میکنند.
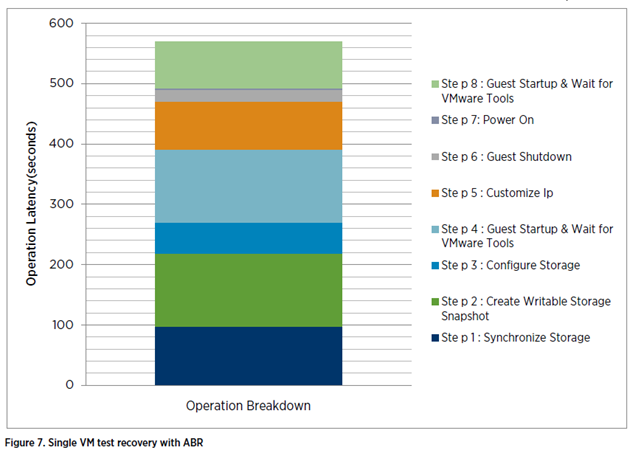
همانطور که در شکل بالا مشاهده میشود، اقدامات 4 و 8 که هردو شامل راهاندازی Guest بوده و انتظار برای VMware Tools می باشند بخش قابل توجهی از زمان کلی بازیابی را به خود اختصاص دادهاند. با یک Boot Storm، این تاخیرات میتوانند به عنوان نتیجهI/O Bottlenecks یا هرگونه Bottlenecks منابع که پلتفرم ما ممکن است با آن مواجه شود باشد.
پارامترهایی که بطور موثر به کنترل Boot Storm کمک میکنند به شرح زیر می باشد:
- Locateکردن پوشه SRM و یافتن پوشه config در آن
- پیدا کردن فایل vmware-dr.xml
- استفاده از یک ویرایش کننده متن مانند Notepad برای ویرایش این فایل.
- جستجوی بخشی در این فایل که با <Config> مشخص شده
- اضافه کردن خطوط مقابل میان Tagهای <Config> و </Config>
Hostهای Standby در سایت بازیابی و فعالسازی DPM
Site Recovery Manager در همکاری با vSphere ماشینهای مجازی را بازیابی میکند حتی در Hostهای Standby، اگر کلاستر سایت بازیابی دارای چندین Host Standby باشد، SRM با کمک DPM هرگونه Host Standby موجود در کلاستر را روشن مینماید. سپس SRM با همکاری DRS از این Hostها برای بازیابی ماشینهای مجازی در طی یک بازیابی آزمایشی و واقعی استفاده میکند. زمانی که ماشینهای مجازی در طی بازیابی روشن هستند SRM در واقع DPMها را از حالت خودکار خارج میکند تا از استقرار Hostها در حالت Standby جلوگیری نماید. این امر پس از اتمام موفق بازیابی، تنظیمات کلاستر DPM را به حالت اولیه برمیگرداند، این فرآیند صرف نظر از اینکه ما دارای DPM فعال برای کلاسترهای خود باشیم یا خیر، برای DPM رخ خواهد داد.
بازیابی ماشینهای مجازی تنها زمانی اتفاق میافتد که SRM خارج کردن تمامی Hostهای ESXi از حالت Standby را به پایان رسانده باشد. این Hostهای ESXi که درحالت Standby قرار دارند بطور همزمان روشن میشوند. فرآیند روشن کردن آنها یک سربار ایجاد میکند که در واقع حداکثر زمان صرف شده برای خارج کردن تمامی Hostها از حالت Standby است. بطور کلی، سربار ذکر شده در مقایسه با منفعت عملکرد زمان بازیابی ناچیز است بخاطر اینکه Hostهای ESXi بیشتری در دسترس قرار دارند. از آنجایی که این سربار با افزایش تعداد ماشینهای مجازی تغییر نمیکند، درصورت داشتن تعداد زیادی از ماشینهای مجازی حفاظت شده میتوان سود بیشتری از عملکرد حاصل نمود. نتایج کلیدی کهمی توان گرفت به شرح زیر می باشد:
- نتایج کلیدی:
- تعداد Hostهای بیشتر، هماهنگی بیشتری برای بازیابی ماشینهای مجازی به دنبال دارد و نتایج بازیابی در زمان کمتری حاصل میگردند.
- به هنگام محافظت از ماشینهای مجازی، ایجاد گروههای حفاظتی به ما اطمینان میدهد که Hostهای سایتهای بازیابی که تحت موجودی مربوط Map شدهاند در حالت روشن مناسبی هستند، در غیر این صورت، SRM از آن Hostها برای ایجاد ماشینهای مجازی Placeholder استفاده نخواهد کرد.
- زمانی که ماشینهای مجازی در طی بازیابی روشن میشوند، SRM اقدام به قرار دادن DPM در حالت دستی یا Manual میکند تا از قرارگیری Hostها درحالت Standby جلوگیری کند. این امر DPM را پس از اتمام موفق بازیابی درحالت اصلی خود قرار میدهد.
اولویت بالا و تعلیق ماشینهای مجازی
در یک پروژه بازیابی، ماشینهای مجازی بازیابی شده به پنج گروه مختلف ارجاع داده میشوند، SRM همچنین عملکرد تنظیم وابستگیها را در تمامی ماشینهای مجازی فراهم میسازد. زمان بازیابی با افزایش وابستگی در تمامی ماشینهای مجازی مجزا یا گروههای ماشینهای مجازی افزایش مییابد. این امر هم در بازیابی آزمایشی و هم در بازیابی واقعی رخ میدهد.
Chainکردن گروههای ماشین مجازی نسبت به Chainکردن آنها بطور مجزا ایده بهتری است. این بدان معناست که گروههای دارای اولویت باید اول استفاده شوند تا وابستگی مورد نظر و ترتیب شروع به کار ماشینهای مجازی تعیین گردد، نه اینکه بطور مستقیم از عملکرد وابستگیهای ماشین مجازی شروع گردد، زیرا شروع به کار ترتیبی ماشینهای مجازی مجزا بر RTO تاثیر دارد، گروهبندی وابستگیهای ماشین مجازی در گروه دارای الویت، معمولا بهترین و ایمنترین ایده است زیرا ماشینهای مجازی درون هر گروه دارای الویت بطور موازی شروع به کار میکنند.
همچنین میتوان SRM را به منظور تعلیق ماشینهای مجازی در طی بازیابی تنظیم نمود، باید توجه داشت که تعلیق ماشینهای مجازی یک عملیات Resource-Intensive ممکن است بسته به تنظیم ماشین مجازی تعلیق شده طول بکشد. RTO کلی ما ممکن است درصورت تعلیق حجم زیاد ماشینهای مجازی افزایش یابد، درحالی که، نکته مثبت این امر این است که تعلیق ماشینهای مجازی منابع پلتفرم را خالی میکند که بعدها ممکن است برای بازیابی سایر ماشینهای مجازی که بخشی از پروژه بازیابی هستند استفاده گردند. نتیجه گیری هایی که می توان کرد به صورت زیر می باشد:
- برنامهریزی الویتها و وابستگیهای میان ماشینهای مجازی که قرار است بازیابی شوند مهم است و در نتیجه تنها برای تعدادی از ماشینهای مجازی، وابستگی تعیین میگردد. چنین وابستگیهایی زمان بازیابی را تحت تاثیر قرار میدهند.
- پیکربندی وابستگیهای ماشین مجازی در تمامی گروههای دارای الویت بجای تنظیمکردن هر وابستگی ماشین مجازی بطور مجزا بسیار توضیه میشود زیرا ماشینهای مجازی درون هرگروه دارای الویت بطور موازی آغاز به کار میکنند.
- تعلیق ماشینهای مجازی در سایت بازیابی همچنین زمان بازیابی را تحت تاثیر قرار میدهند.
ابزارهای پیشرفته تنظیمات/VMware
SRM تنظیمات پیشرفته مشخصی را ارائه میدهد که میتوان در هر سایت تنظیم نمود، این تنظیمات میتوانند عملکرد کلی عملیات SRM و عملیات حیاتی مانند بازیابیهای واقعی و آزمایشی را تحت تاثیر قرار دهند.
هرزمان که موجودی سایت حفاظت شده تغییر مییابد، SRM یک رایانش جدید LUN Group را اجرا میکند. اگر چندین ماشین مجازی را به دیتاسنتر اضافه نموده یا بطور کلی موجودی را تغییر دهیم، میتوانیم با تنظیم storage.minDsGroupComputationInterval به زمان تقریبی که تغییر به آن نیاز دارد، SRM را پیش از انجام رایانش دیگر منتظر نگه داریم. برای مثال، تنظیم storage.minDsGroupComputationInterval به یک مقدار عددی این را به SRM میرساند که باید حداقل آن تعداد ثانیه بین هر دو Task متوالی LUN Group Computation زمان وجود داشته باشد. منظور از این تنظیمات این است که در زمان وقوع تغییرا بسیار در موجودی، Taskهای LUN Group Computation کمتر رخ دهند.
VMware توصیه می کند که VMware Tools در تمامی ماشینهای مجازی حفاظت شده نصب گردند، بسیاری از عملیات بازیابی SRM مشروط بر نصب درست VMware Tools در ماشینهای مجازی حفاظتشده هستند تا Taskهای زیر را انجام دهند:
- به هنگام روشن نمودن ماشینهای مجازی برای OS Heartbeat و به هنگام تنظیم دوباره ماشین مجازی بازیابی شده، برای تغییر شبکه صبر نمایید، SRM برای گزارش OS Heartbeat و تکمیل تغییرات شبکه به VMware Tools وابسته است. با این حال، اگر دارای VMware Tools نصب شده در هیچگونه از ماشینهای مجازی حفاظتی خود نمی باشد، میتوان مقادیر Timeout را برای recovery.powerOnTimeout و recovery.customizationTimeout تا صفر تنظیم نمایید.
- برای خاموش شدن ماشینهای مجازی در سایتهای حفاظتشده صبر کنید.
- در طی انتقال تعیین شده، Site Recovery Manager تلاش میکند تا ماشینهای مجازی را در سایت حفاظت شده به آرامی خاموش کند. پیش از آنکه Site Recovery Manager با شدت یک ماشین مجازی را خاموش کند، سعی میکند تا Guest OS را خاموش نماید. اگر خواستید که بدون خاموش کردن آرام Guest OS، ماشین مجازی را خاموش کنیم، میتوانیم recovery.skipGuestShutdown را در منو Advanced Settings به True تنظیم نماییم.
توجه: اگر ماشینهای مجازی دارای VMware Tools نصب شده نیستند و Timeout خاموشی Guest به مقداری غیر از صفر تنظیم شده است، پروژه بازیابی به پس از مرحله « Shutdown VMs at Protected Site» نخواهد رسید. در این صورت اگر میخواهیم پروژه بازیابی ما پیشرفت نماید میتوان recovery.skipGuestShutdown را به Ture تنظیم نمود.
مشخص کردن یک Datastore Nonreplicant برای فایلهای Swap
هر ماشین مجازی نیازمند یک فایل Swap است که معمولا در همان Datastore سایر فایلهای ماشین مجازی ایجاد میشود. زمانی که از SRM استفاده میشود، این Datastore، همسانسازی میشود. برای جلوگیری از همسانسازی فایلهای Swap آنها باید بر روی یک Non-replicated Datastore ایجاد شوند.
اگر برای فایلهای Swap از یک Non-replicated Datastore استفاده شود، باید یک Non-replicated Datastore برای تمامی کلاسترهای محافظت شده در هر دو سایت محافظت شده و بازیابی ایجاد گردد. برای انجام این کار باید:
- در vSphere Client بر روی یک کلاستر ESXi راست کلیک کرده و بر روی Edit Settings کلیک میکنیم.
- در پنجره Setting کلاستر بر روی Swapfile Location کلیک کرده و Swapfile Store موجود در Datastore که توسط Host مشخص شده را انتخاب میکنیم و بعد بر روی Ok کلیک میکنیم.
- برای هر Host در کلاستر، یک Non-replicated Datastore انتخاب میکنیم.
- بر روی Tab Configuration کلیک میکنیم.
- در نوار Swapfile Location بر روی Edit کلیک میکنیم.
- در پنجره Virtual Machine Swapfile Location یک Non-replicated Datastore انتخاب کرده و بر روی Ok کلیک میکنیم.
مزایای زمان بازیابی برای حذف فایل های Swap
SRM برای حذف فایلهای Swap موجود در یک Replicated Datastore در هنگام بازیابی در سایت بازیابی، با vCenter Server تماس از راه دور برقرار میکند. اگر فایلهای Swap در Non-replicated Datastore وجود داشته باشند، این مرحله کنار گذاشته میشود که این کار باعث سرعت بخشیدن به بازیابی میگردد. این امر همچنین باعث جلوگیری از هدر رفتن Bandwidth شبکه در هنگام Replication میان دو سایت شده و این امر به ویژه اگر از فضای NFS استفاده شود بسیار موثر است.
VMware vCenter Site Recovery Manager قابلیتهای پیشرفتهای برای مدیریت Disaster Recovery، آزمایش بدون اختلال و Failover خودکار را فراهم میکند.
- توصیه میشود که دیتابیس SRM تا حد امکان نزدیک به سرور SRM نصب شود تا باعث کاهش زمان Round-trip بین آنها شود. بدین ترتیب عملکرد زمان بازیابی به دلیل Round-tripها به سرور پایگاه داده، لطمه زیادی نخواهد دید.
- داشتن Volumeهای کمتر ولی جامعتر از NFS راه کار مناسبی است تا زمان اختصاص دادهشده به نصب تعداد زیادی از این Volumeها در حین بازیابی کاهش یابد.
- فعال سازی DRS در یک سایت بازیابی یک روش موثر است.
- Hostهای بیشتر همزمانی بازیابی ماشینهای مجازی را افزایش میدهد و زمان بازیابی را کوتاهتر میکند.
- قبل از محافظت از ماشینهای مجازی، Hostهای بازیابی سایت باید از حالت Standby خارج گردند تا برای ایجاد ماشینهای مجازیPlaceholder توانمند شوند.
- VMware Tools برای دستیابی دقیق به اعلانهای تغییر Heartbeats و شبکه در همه ماشینهای مجازی محافظت شده نصب شوند.
- از این که هر اسکریپت یا Call-out Prompt داخلی به صورت نامحدود مانع بازیابی نمیشود، باید اطمینان حاصل کرد.
- فایلهای Swap باید برای یک Non-replicated Datastore مشخص شوند. این کار از هدر رفتن Bandwidth شبکه در زمان Replication میان دو سایت جلوگیری میکند و تماسهای از راه دور به vCenter Server را در زمان بازیابی برای حذف فایلهای Swap برای همه ماشینهای مجازی را کاهش میدهد و به طور کلی به سرعت بخشیدن به بازیابی کمک میکند.
