در مقاله “آنالیزی از نرم افزار Splunk” به معرفی نرم افزار Splunk و همچنین در مقاله “مفهوم Big Data در دنیای تکنولوژی” به ارائه مفهوم Big Data و مثالی در این زمینه پرداخته شد. در این مقاله به تلفیق استفاده از این دو تکنولوژی و بررسی Splunk جهت تجزیه و تحلیل Big Data می پردازیم.

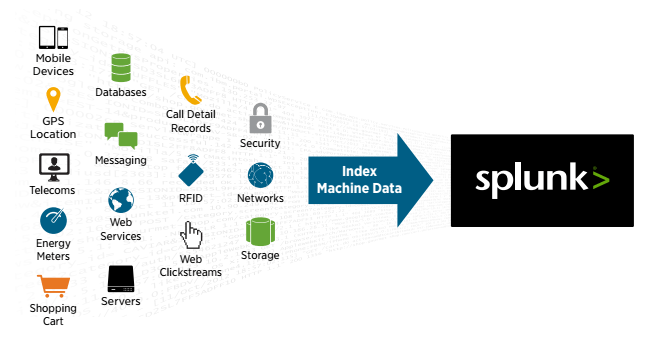
- دادههای خام را به داده هایی با ارزش برای کسبوکار خود تبدیل نمایید.
ماشین های سازنده ی Big Data
تمام برنامهها، حسگرها، سیستمها، سرورهای وب و دیگر زیرساختهای فناوری، همهروزه و در هر میلیثانیه دادههایی را تولید میکنند. این دادههای ماشینی، یکی از پیچیدهترین حوزههای Big Data هستند و رشد فزایندهای دارند. این دادهها بدلیل اینکه شامل رکوردهای نهایی از تعاملات کاربر، رفتار مشتری، فعالیت حسگرها، رفتار ماشین، تهدیدهای امنیتی، فعالیتهای جعلی و موارد دیگر می باشند، بسیار ارزشمند هستند.
استفاده از دادههای ماشین، دشوار است. این دادهها با انبوهی از منابع ناهمگون، در قالبهایی بیساختار، تولید میشوند؛ بنابراین تطبیق آنها با الگو (Schema) های بی دوام و شکننده ی ازپیشتعریفشده را دشوار میسازد. چالش سازمانها شامل درک، پردازش و تحلیل دادههای ماشینی با استفاده از روشهای سنتی مدیریت داده و یا رفتار بهموقع می باشد. راهکارهای اطلاعات،Data Warehouse ، و تجزیهوتحلیل را نمیتوان بهراحتی برای این دادههای بیساختار، با حجم بالا و پویا مهندسی نمود.
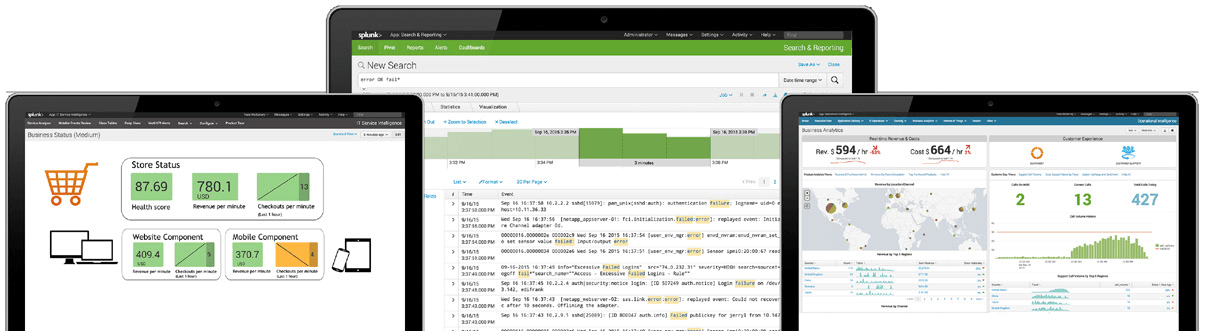
Splunk: پلتفرمی برای تجزیه و تحلیل Big Data
نرمافزار Splunk، ارزش پنهان دادهها را نمایان می کند. با قابلیت وارد نمودن اطلاعات از سایر ابزارها، میتوان علاوه بر ارزش یک زیرمجموعه، ارزش طیف کامل دادهها را بدست آورد. از دیگر مزایای استفاده از Splunk این است که می توان تمام دادهها را یکجا گردآوری، نمایه گذاری(Index)، جستجو، تحلیل و نمودار (visualize) نمود.
به عبارتی دیگر؛ Splunk روشی است یکپارچه، جهت سازماندهی و استخراج اطلاعات Real-Time از مقادیر انبوه دادههای ماشینیِ (تقریباً) از تمامی منابع٫
استفاده و بهکارگیری آسان
Splunk Enterprise و Splunk Cloud راهکارهای یکپارچهشده، End-to-End و Real-Time برای دادههای ماشینی به شمار می آیند. راهکارهای Splunk از گردآوری فراگیر تا نمایهگذاری (Index) دادههای ماشینیِ تقریباً هر منبع گرفته تا گزارشدهی و تحلیل جامع از طریق Search Processing Languageیا به اختصار SPL تا جستجو و تحلیل دادههای گذشته و Real-Time، بیشترین بهره را از دادههای ماشینی میگیرند. تنها با چند کلیک به دادههایتان وصل شوید و بهراحتی داشبوردهای قدرتمند خلق کنید.

Big Data در مقیاس سازمانی
نرمافزار Splunk اقدام به مقیاسبندی مینماید تا هر روز صدها ترابایت داده را در سراسر زیرساخت Hybrid Cloud، چنددیتاسنتری و چندجغرافیایی گردآوری و فهرست کند. به دلیل آنکه اطلاعات حاصل از دادهها، ماموریت حیاتی هستند، نرمافزار Splunk حتی زمانی که محیط محاسباتی توزیعی و کمهزینهی خود را Scale Out میکنید، خودترمیمی (Resilience) را همچنان ارائه میدهد.
اطلاعات دادههای گذشته و Real-Time
به راحتی می توان دادههای خود در Splunk را برای الزامات ممیزی و پذیرش در Hadoop آرشیو نمود. جهت انجام این کار باید، آنها را با دادههای موجود در Hadoop ، Join کنید تا بدون هیچگونه نگرانی بیشترین بهره برداری از داده ها به عمل آید.
Hunk: Splunk Analytics for Hadoop نیز امکان Queryها و داشبوردهای یکپارچه در دادههای بیساختارِ Splunk Enterprise و Hadoopرا ایجاد نموده، و یک Single-Pane-of-Glass در دادههای گذشته و Real-Time فراهم میسازد. در واقع می توان دادههای چند ماه یا سال را در یک واسط کاربری ساده و روان تحلیل و نمودار نمود.
اضافه نمودن Context و گسترش آن با دادههای هموندی (Relational Data)
میتوان دادههای ساختارمند را از دیتابیس های هموندی وData Warehouse های سازمان، با دادههای ماشینی در نرمافزار Splunk یکپارچهسازی کرد تا سطوح عمیقتری از اطلاعات عملیاتی و اطلاعات کسبوکار از Big Data کسب نمود. Splunk DB Connect یکپارچهسازی مطمئن و مقیاسپذیری بین نرمافزار Splunk و دیتابیسهای هموندی برقرار مینماید. Splunk ODBC Driver این امکان را فراهم می سازد تا با استفاده از نرمافزار هوشمند کسبوکار انتخابی، دربارهی دادههای ماشینی گزارش تهیه نمود.
