تیمهای Odern IT و DevOps با محیطهای بسیار پیچیده مواجه میشوند که شناسایی و رفع Real-time مشکلات اساسی را سختتر میکند. به منظور غلبه بر این مشکل، کاربران میتوانند از مانیتورکردن هایی مجهز به ML و راهکارهای DevOps موجود در یک پلتفرم توسعهپذیر دارای بروزترین تجزیه و تحلیل دادهها و قابلیتهای AI/ML بهره ببرند. در این مطلب ما چگونگی استفاده از Splunk Machine Learning Environment یا SMLE را کشف میکنیم تا بطور دقیقتر Error Windowهای اخلالگر را در Logهای سرور برنامه کاربردی شناسایی کنیم و تعداد رویدادهایی که نیازمند مرور دستی هستند را کاهش دهیم. همچنین الگوریتمهای Streaming ML که Built-In میباشند را پیادهسازی کرده تا الگوهای اخلالگر را در Logها بطور Real-time شناسایی کنیم. با تقسیمبندی این امر به اقدامات سادهتر، ما به کاربران خود چگونگی استفاده از قابلیتهای اولیه اسپلانک در استفاده از Logها، پردازش مقدماتی دادهها، بکارگیری ML بطور Real-time و مصورسازی نتایج را نشان خواهیم داد.

چرا باید از شناسایی اختلال استفاده کنیم؟
شناسایی اختلال به سازمانها این امکان را میدهد تا در طی Streamکردن، الگوها و رویدادهای مخرب را شناسایی کنند. شناسایی اختلال میتواند برای تشخیص تغییرات خارج از انتظار و روال معمول در دادهها مورد استفاده قرار گیرد، چه شناسایی Loginهای تقلبی و هشدار Spikeهای معیارهای KPI باشد، چه شناسایی استفاده غیرمعمول از منابع، این امر نشانههای اولیه مشکلات عملیاتی بنیادین را برای تیمهای IT و DevOps فراهم میکند.
شناسایی اختلال برای موارد استفاده DevOps
بسیاری از سازمانها با حجم بسیار زیاد و پیچیدگی دیوانه کننده دادهها مواجه هستند که روایتگر یک چالش عظیم برای سازمانهای IT است. به عنوان مثال صنعت Telco را درنظر میگیریم که به منظور رسیدن به 77.5 اگزابایت از ترافیک دادههای تحرکپذیر در ماه در سراسر جهان سازمان یافته است. مدیریت چنین محیطهایی که مدام درحال گسترش هستند از طریق یک رویکرد استاتیک و مبتنی بر قانون کافی نیست. تیمهای DevOps مدرن به هنگام مانیتورکردن ناشناختهها بطور روزافزون بر راهکارهای مبتنی بر AI/ML شناسایی اختلال وابسته میشوند که هشدارهای خسته کننده را کاهش میدهند و یا قابلیت دید Logهای برنامههای کاربردی را ایجاد میکنند. بطور گسترده این موارد میتوانند به موارد مقابل دسته بندی شوند: تجزیه و تحلیل پیشبینانه، هشدارهای هوشمند و عیبیابی/ رفع رویداد.
همانطور که میدانیم، Machine Learning Toolkit یا MLTK مربوط به اسپلانک به کاربران این امکان را میدهد تا با رویکرد قدیمی آموزش مدلها در مقابل دادههای قدیمی یا با روشهای تجزیه و تحلیل استاتیک، راهکارهای شناسایی اختلال را بسازند. جدیدترین محصول ML از اسپلانک، Splunk Machine Learning Environment یا SMLE یک راهکار Real-time شناسایی اختلال را همراه با جدیدترین قابلیتهای تجزیه و تحلیل Streaming و AI/ML که در طی Streamکردن به یادگیری و پیش بینی مشغول هستند ارائه میدهد.
با SMLE، یک گردش کار ساده برای ایجاد راهکار شناسایی اختلال شامل چهار مرحله است:
- ساخت و Streamکردن دادههایی که Logهای سرور تولیدی را با SLP2 شبیهسازی میکنند
- استخراج دادهها و تبدیل دادهها با استفاده از اپراتورهای SPL2
- استفاده از الگوریتمهای ML Streaming به منظور بکارگیری آستانههای انطباقی بطور Real-time
- استخراج دیدگاههای حاصل از نتایج و تصویرسازی اختلالات

گام اول: Streamکردن دادهها از Logهای سرور با استفاده از SPL2
با Streamکردن دادهها به Pipeline خود فرآیند را آغاز میکنیم، در این مثال، ما دادهها را از یک AWS S3 Bucket که Logهای خام سرور مربوط به یک هفته را در آن آپلود میکنیم بیرون میکشیم، Pipeline دادههای SPL2 که دادهها را از S3 Bucket به محیط شبکه Jupyter میآورد مشاهده میکنیم و خروجی ما یک سری از Logهای خام است.
زمانی که دادههای خام را داریم، با کمک مجموعهای از عملیات ساده SPL2 قابلیتهای مرتبط را استخراج کرده و دادهها را به منظور شناسایی الگوهای اخلالی تبدیل میکنیم.
در این فاز دو مرحله را اجرا میکنیم:
- استخراج Timestampهای Logهای مربوط به Error Statement
- تبدیل Dataset با جمعآوری تعداد Errorها در هر یک ساعت
در این قسمت Pipeline دادههای SPL2 که اولین سکانس استخراج دادهها را انجام میدهد آمده است. خروجی این بخش یک سری از Timestampهایی هستند که در آنها Errorها در Logهای سرور گزارش شدهاند.
سپس تعداد Timestampهای یک ساعت را جمعآوری میکنیم، در اینجا یک افزونه از Pipeline SPL2 آمده است که این عملیات را انجام میدهد. خروجی شامل یک ستون جدید «count» میشود که نشاندهنده تعداد Error رخ داده در آن ساعت از هفته است.
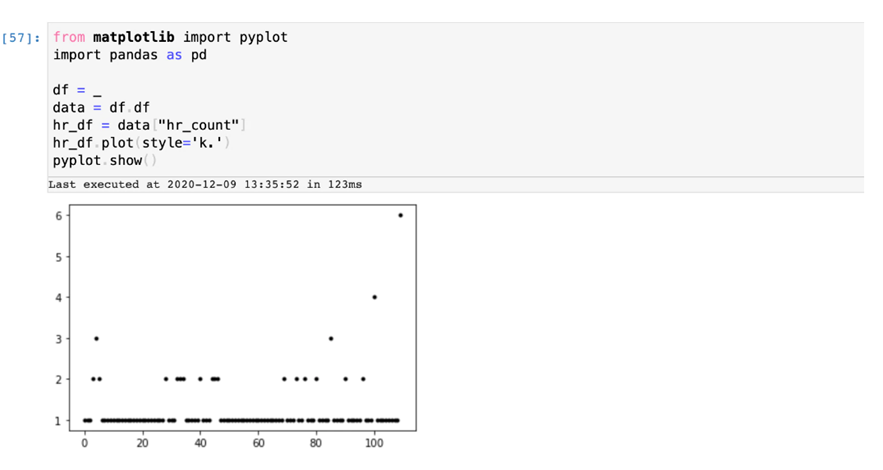
حال این میزانها را ترسیم میکنیم تا بفهمیم کدامیک عادی بوده و کدام خارج از محدوده است. با استفاده از یک اسکریپت ساده Python که درون دفترچه SPL2 Jupiter قرار دارد میتوان به سادگی میتوان خروجی را نمونه برداری کرد تا پی برد تعداد کمی از مقادیر 3 یا بیشتر وجود دارد.
گام سوم: استفاده از الگوریتمهای Streaming ML به منظور بکارگیری آستانههای انطباقی بطور Real-time
در این گام ما با بکارگیری الگوریتم Built-In اسپلانک، آستانه انطباقی را بطور Real-time ایجاد میکنیم که پیرو روش Quantiles است. این عملیات Stream را بطور Real-time پروفایل کرده و یک لیست ترتیبی از مقادیر توزیعشده ایجاد مینماید. اساسا این الگوریتم میزان احتمال وقوع یک میزان را در آن Stream پیشبینی کرده مقادیر خارج از محدوده با مشاهدات خارج از آستانه همخوانی دارد. ما از این کیفیت برای شناسایی تعداد Errorهای غیر محتمل اما اخلالگر استفاده میکنیم، در اینجا یک افزونه از Pipeline دادههای SPL2 که تاکنون ساختهایم نشان داده شده است.
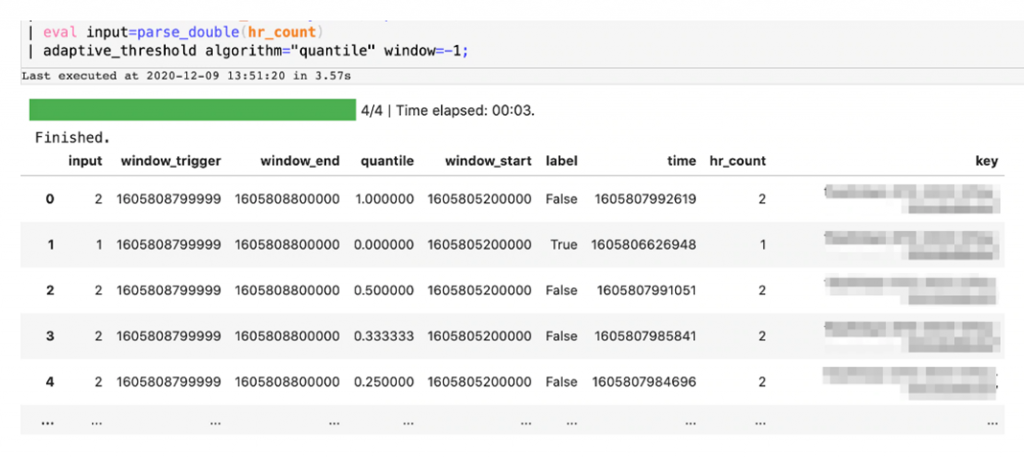
گام چهارم: استخراج دیدگاهها
مقادیر آستانهای آزاد شده که خروجی Pipeline دادهها هستند نشاندهنده احتمال یافتن مقادیر مشابه دیگر در Stream هستند، در شناسایی اختلال، ما از یک Percentile آستانهای استفاده میکنیم تا پنجرههای مخرب را فیلتر کرده و با Python از مصورسازیهای ساده استفاده کنیم تا آن اختلالها ترسیم شوند.
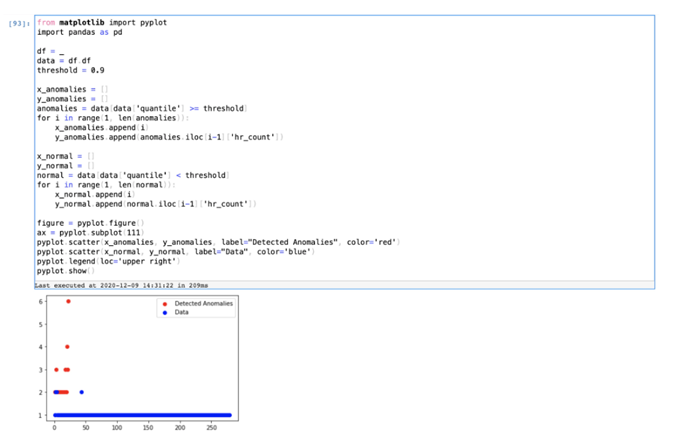
به منظور عملی کردن دیدگاهها، پلتفرم AI/ML اسپلانک قابلیتهایی را ارائه میدهد تا با ساخت چندین Dashboard بتوان اختلالات را شناسایی نمود و بعد، هشدارها و عملیات گردشهای کاری را ایجاد کرد تا به این هشدارها پاسخ داده شود.
راهکار End-to-End با SMLE
ما یک راهکار را برای شناسایی اختلال نشان دادیم که ورای استفاده از SMLE است، Splunk ML Environment یا SMLE یک پلتفرم برای ساخت و پیادهسازی ML در مقیاس درونی اکوسیستم اسپلانک است. با گسترش ویژگیهای Splunk که کاربران به آن علاقه مند هستند و مجموعهای از علوم دادهها و قابلیتهای عملیاتی، SMLE این امکان را به کاربران Splunk و دانشمندان علوم دادهها میدهد تا در ساخت راهکارهایی که ترکیبی از Libraryهای ML و SPL را در بر دارند همکاری کنند.
