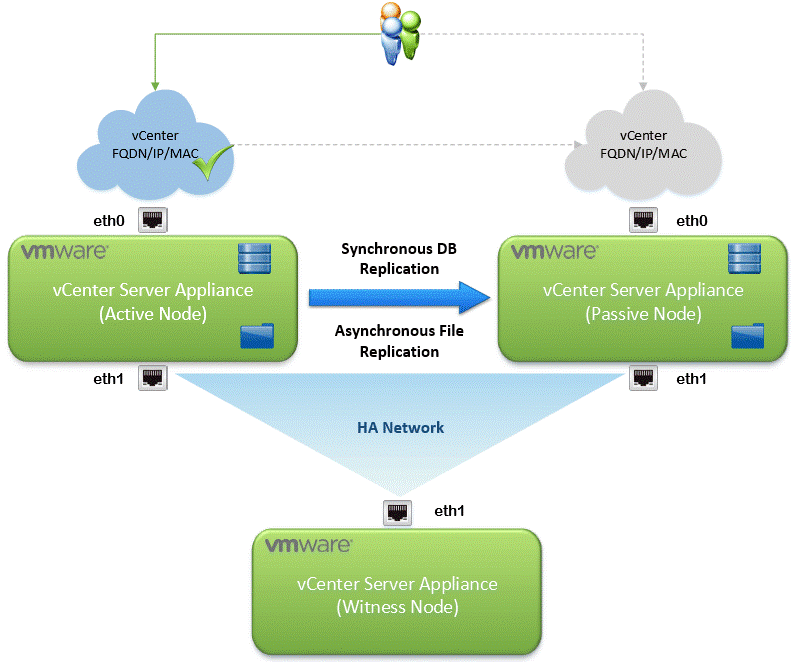
vCenter High Availability یا به اختصار VCHA در نوامبر سال 2016 در vSphere 6.5 معرفی شده بود. از آنروز تابهحال تیم بازاریابی فنی شرکت VMware زمان زیادی را برای ایجاد محتوا و صحبت درخصوص VCHA صرف نمودهاند و بخش اعظم این اطلاعات و مستندات در vSphere Central قابل دسترسی است. علیرغم وجود تمام این اطلاعات، هنوز هم سؤالات متداول و ذهنیتهای اشتباهی درخصوص این ویژگی وجود دارد. از آنجاییکه در مقالات پیشین بهصورت مفصل به معرفی VMware vCenter Server High Availability پرداختهایم (از طریق لینک های موجود در سایت میتوانید به مقالههای مرتبط دسترسی پیدا کنید) در این مطلب به بررسی تفاوتهای پیادهسازی ساده و پیشرفته آن، مواردی که باید حین پیادهسازی مدنظر قرار داد و ابعاد عملیاتی VCHA خواهیم پرداخت.

پیادهسازی ساده یا پیشرفته
یکی از متدوالترین سؤالات و ذهنیتهای غلطی که وجود دارد این است که برای بهرهمندی از تمام ویژگیهای VCHA حتماً باید با استفاده از گردشکار پیشرفته (Advanced workflow) آن را پیادهسازی نمود که این امر از پایه و اساس غلط است. در واقع فارغ از نوع پیادهسازی، VCHA همواره به یک گونه میباشد. توصیهی ما این است که در صورت امکان، برای پیادهسازی VCHA از حالت ساده استفاده نمایید، شاید بهتر بود که این روشهای پیادهسازی اتوماتیک (ساده) و دستی (پیشرفته) نامگذاری میشدند.
در روش ساده ساختار بهصورت اتوماتیک برای کاربر پیریزی میشود، یعنی اضافه نمودن دومین کارت شبکه، Cloning، تغییر سایز Witness VM و اِعمال Ruleهای DRS Anti-Affinity تماما به صورت خودکار راهاندازی میشود اما در روش پیشرفته باید تمامی این موارد بهصورت دستی انجام بپذیرند. علاوهبراین، نیاز به اعمال تغییرات در VCHA Cluster است، کارهایی همچون تغییر Certificateها، تغییر IP متعلق به vCenter Server یا Restoreنمودن vCenter Server. اگر از گردشکار پیشرفته برای پیکربندی VCHA استفاده کرده باشیم، کارهای زیادی را باید دوباره انجام دهیم و اگر از گردشکار ساده استفاده کرده باشیم میتوان در عرض 30 ثانیه VCHA را دوباره بهحالت آمادهبهکار در آورد.
جهت مشاوره رایگان و یا راه اندازی زیرساخت مجازی سازی دیتاسنتر با کارشناسان شرکت APK تماس بگیرید. |
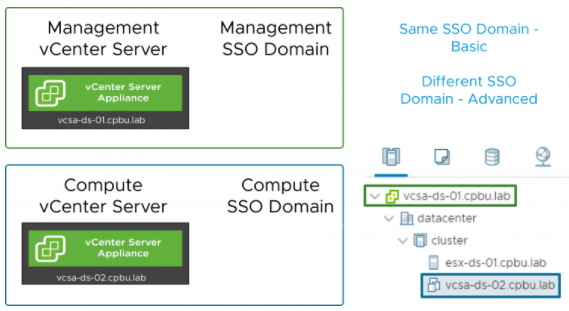
شاید با خودتان فکر کنید پس چه زمان باید از حالت پیشرفته استفاده نمود؟ استفاده از حالت پیشرفته برای زمانی که vCenter Server ما بر روی یک Management Cluster که در دامین SSO متفاوتی قرار دارد، مناسب است. برای مثال فرض کنید یک Compute vCenter در یک دامین Compute SSO داریم، اما vCenter در Inventory متعلق به Management Center و دامین Management SSO قرار دارد؛ در چنین شرایطی به استفاده از پیادهسازی پیشرفته نیاز داریم. اگر آن Compute vCenter Server در دامین SSO مشابه با Management vCenter Server قرار داشته باشد که بر روی آن VCHA را فعالسازی میکنیم، میتوانیم از حالت ساده استفاده کنیم. یک دلیل دیگر استفاده از حالت پیشرفته زمانی است که بخواهیم Nodeهای VCHA خود را میان چندین سایت تقسیم کنیم که در بخشهای بعدی بیشتر به این امر خواهیم پرداخت.
بسیاری از کاربران میتوانند با استفاده از حالت ساده کار خود را پیش ببرند و نیازی به دستوپنجه نرم کردن با سختیهای گردشکار پیشرفته نداشته باشند. بهیاد داشته باشید که نتیجه فارغ از اینکه از حالت پیشرفته یا ساده استفاده میکنید، یکسان است و VCHA فارغ از شیوهی پیادهسازی، همان VCHA است و گمان نکنید که استفاده از حالت پیشرفته الزامی است.
محافظت از vCenter Server با استفاده از VCHA
این مبحث، مقوله پیچیدهای است پس تلاش بر این است که آن را به چند بخش قابل درک تقسیم کنیم، بنابراین در ابتدا بیاید دریابیم که VCHA از ما دربرابر چه خرابیهایی محافظت بهعمل میآورد. یک VCHA Failover، یعنی انتقال سرویسهای فعال vCenter از ماشین مجازی دچار مشکل به ماشین مجازی غیر فعال و سالم یا به عبارتی انتقال از Active Node به Passive Node در زمان خرابی ماشین مجازی فعال، که علت خرابی میتواند یکی از حالتهای ذیل باشد:
- خرابی کامل سختافزاری یا هاست
- خرابی شبکه یا Isolation
- خرابیهای Storage
- خرابی سرویس های vCenter Server
- خرابی سیستم عامل
با در نظر گرفتن مشکلات بالا و توانایی VCHA برای بازیابی از آنها، VCHA میتواند راهکاری با دسترسپذیری بالا برای vCenter Server باشد. توجه کنید که اگر چندین سایت داشته باشیم و بخواهیم از vCenter Server در برابر خرابی کامل سایتی حفاظت بهعمل آوریم چطور؟ این امر شدنی است، ولی مواردی وجود دارد که باید به آنها توجه داشته باشیم. مهمترین عاملی که حین استفاده از VCHA برای حفاظت از vCenter Server دربرابر خرابی سایت باید درنظر داشته باشیم این است که VCHA یک راهکار HA است نه یک راهکار (Disaster Recovery (DR. درصورتی که VCHA بهدرستی پیکربندی شده باشد، بهخوبی vCenter Server Appliance ما را به یک Node جایگزین که در ُسایت دیگری درحال اجراست، بازیابی مینماید. اما، تمامی بارهای کاری و هاستها بدون هرگونه DR Orchestration، بر روی سایت خراب باقی خواهند ماند. پیشنهاد ما این است که بهجای استفادهی از VCHA، از یک استراتژی DR Orchestration کامل برای حفاظت از vCenter Server در برابر خرابی سایتی استفاده گردد.
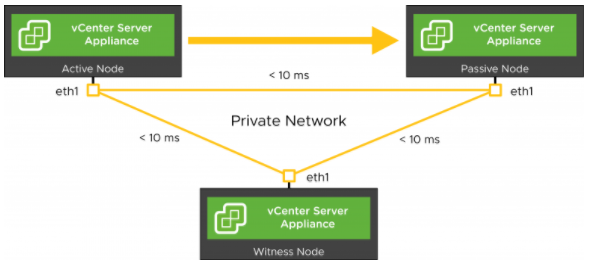
نکتهی شایان ذکر دیگر این است که یک پیشنیاز زمانی10ms بین هر سه Node وجود دارد(Round-Trip Time) و باید تأثیر زیرساخت مناسب شبکهای برای VCHA را درک نمود. اگر هیچ Stretched L2ی وجود نداشته باشد (حال یا از طریق یک تکنولوژی رایج همچون OTV کمپانی Cisco یا یک Overlay همچون VXLAN)، آدرس IP متعلق به vCenter Server باید حین یک رویداد Failover دچار تغییر شود. این عمل بهصورت اتوماتیک انجام میشود اما DNS خیر. رکوردA متعلق به vCenter Server توسط همان سرویس DNSی کنترل میشود که در محیط ما استفاده میشود و حتی اگر بهروزرسانی آن رکورد به آدرس IP جدید را خودکارسازی کنیم، این احتمال وجود دارد که بهدلیل DNS TTL، تکثیریابی (Propagation) و Caching، مشکلاتی گذرا پیش بیایند. این امکان وجود دارد که این مکانیزمهای گذرای DNS، بتوانند از شروعبهکار صحیح Passive Node ما جلوگیری بهعمل آورند که با HA بودن این راهکار در تناقض است.
اگر شبکههای Stretched L2 میان سایتها داشته باشیم، این امر نیازی به بحث ندارد چرا که میتوانیم از تغییر IP متعلق به vCenter Server و DNS در هنگام یک Failover اجتناب کنیم. همچنین باید بهخاطر داشته باشیم که برای تقسیم Nodeها میان سایتها، باید از گردشکار پیشرفته استفاده کنیم؛ این بدین معنی است که هر وقت که Upgrade در کار است، Certificateها را جایگزین کنیم و یا VCHA Cluster را دوباره پیادهسازی کنیم، باید VMها را Tear Down کرده و بهصورت دستی Clone بگیریم، سپس آنها را به سایتی که باید در آن اجرا گردند انتقال داده، Witness را تغییر سایز داده و تمام Ruleهای DRS را دوباره راه اندازی کنیم که این امر کار و زحمت زیادی دارد پس از همان ابتدا باید تمام این موارد را مدنظر قرار داد.
هرچند یک سناریوی خاص وجود دارد که ممکن است تقسیم Nodeهای VCHA میان سایتها در آن ثمربخش باشد. اگر درحال اجرای یک Stretched Cluster یا vMSC باشیم، محیط راه اندازی ما برای VCHA بسیار مناسبتر است. اتصال L2 میان سایتها برای Stretched Clusterها و همچنین Stretched Storage یک پیشنیاز است. این موضوع انتقال Nodeها به سایتها را بسیار سادهتر میکند و ما نیازی نیست با پیچیدگی تغییر IP و DNS دستوپنجه نرم کنیم. میتوانیم Ruleهای DRS خود را دوباره پیکربندی کنیم تا Nodeها از هرطرف به Host Groupهای خاص متصل شوند. اما همچنان نیاز داریم که در این سناریو از گردشکار پیشرفته استفاده کنیم چرا که به یک سایت سوم برای Witness VM نیاز داریم و استفاده از گردشکار پیشرفته تنها راهی است که میتوان Witness را به آن سایت سوم رساند، به استثنای زمانی که سایت سومی داشته باشیم که Stretched L2 از دو سایت دیگر داشته باشد. در غیراینصورت، حتی با اینکه ممکن است سادهتر بهنظر بیاید، باز هم باید کارهایی را بهصورت دستی انجام دهیم.
پیشتر در این مطلب به آن اشاره کردیم، اما شایان ذکر است که vCenter High Availability یک راهکار High Availability است نه یک راهکار Disaster Recovery. دلیل این امر این است که VCHA تنها از vCenter Server محافظت مینماید نه از بارهای کاری و هاستهایی که توسط آن مدیریت میشوند. همچنین کار و زحمت نسبتاً زیادی برای راه اندازی VCHA برای اجرا در چند سایت علاوه بر زحمت عملیاتی نگهداری از آن (استفاده از گردشکار پیشرفته) نیز وجود دارد، بنابراین بهترین کار این است که هنگام پیادهسازی VCHA، درصورت امکان از گردشکار ساده استفاده کنیم تا پیادهسازی و نگهداری آن سادهتر باشد. همچنین باید از vCenter Server در درون یک سایت محافظت بهعمل آوریم چرا که احتمال خرابی سختافزاری، شبکهای و ذخیرهسازی بسیار بیشتر از خرابی کامل سایت است.
ــــــــــــــــــــــــ
بررسی نحوه پیادهسازی vCenter High Availability – قسمت اول
بررسی نحوه پیادهسازی vCenter High Availability – قسمت دوم (پایانی)
