
با ارائه نسخه جدید SQL Server 2019، کلاستر Big Data در SQL Server به کاربر امکان نصب کلاسترهای مقیاسپذیر از سرور SQL، اسپارک و HDFS Containerها را، که در Kubernetesها اجرا میشوند، میدهد. این اجزاء با کار کردن در کنار هم توانایی خواندن، نوشتن و پردازش Big Data را از Transact-SQL یا Spark، و همچنین اجازهی ترکیب و آنالیز دادههای با ارزش مرتبط با حجم زیادی از Big Data را به کاربر میدهند.

بررسی کلاستر Big Data
کلاسترهای Big Data در SQL Server قابلیت انعطافپذیری را به کاربر ارائه میدهند تا به هر روشی با Big Data تعامل کنند. بر این اساس کاربر میتواند از منابع داده خارجی Query بگیرد، همچنین Big Data را در HDFS Managed با استفاده از سرور SQL ، ذخیره نموده و یا توسط کلاستر از منابع دادهی خارجی چندین Query بگیرد. بخشهای زیر اطلاعات بیشتری در مورد این سناریوها ارائه میدهند.
مجازیسازی دادهها
کلاسترهای Big Data در سرورهای SQL با اعمال SQL Server PolyBase میتوانند بدون انتقال یا کپی داده، از منابع داده خارجی Query بگیرند. لازم به ذکر است که SQL Server 2019 (15.x) رابطهای جدید را به منابع داده معرفی میکند.

Data lake
کلاستر Big Data در SQL Server شامل یک HDFS Storage Pool مقیاسپذیر است و این موضوع به ذخیره کردن Big Dataهایی که بصورت بالقوه از چند منبع خارجی استفاده میکند، کمک مینماید. هنگامی که Big Data در HDFS در کلاستر Big Data ذخیره میشود، کاربر میتواند دادهها را آنالیز کند، از آنها Query بگیرد و با دادههای مرتبط ترکیب کند.
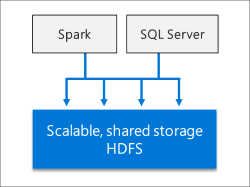
بازار داده مقیاسپذیر
کلاسترهای Big Data در SQL Server، ذخیرهسازی و محاسبات مقیاسپذیری را برای بهبود عملکرد تجزیه و تحلیل دادهها ارائه میدهند. دادهها از منابع مختلفی درNodeهای در نظر گرفته شده در Data Pool به عنوان Cache، جهت آنالیز بیشتر میتوانند استفاده کرده و توزیع شوند.
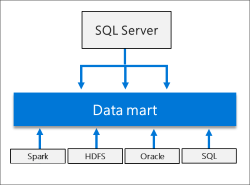
هوش مصنوعی(Al) و یادگیری ماشینی (Machine Learning) یکپارچه
کلاسترهای Big Data در Server SQL، معمولا Taskهای هوش مصنوعی و یادگیری ماشینی را بر دادههای ذخیره شده در HDFS Storage Poolها و Poolهای مختص به دادهها، فعال میکنند. کاربر میتواند با استفاده از R، Python، Scala یا جاوا از Spark و ابزار هوش مصنوعی ساخته شده در سرور SQL بهره ببرد.
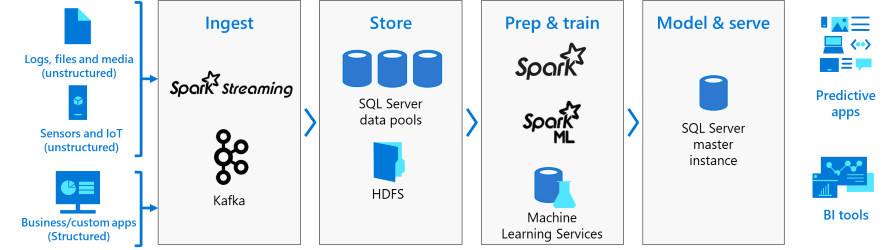
مدیریت و مانیتورینگ ساختار
مدیریت و مانیتورینگ از طریق ترکیبی از ابزار خط دستور، APlها، پورتالها و دیدگاههای مدیریت پویا (Dynamic Management View) ارائه میشوند. کاربر میتواند از Azure Data Studio برای انجام امور مختلف در کلاستر Big Data استفاده کند. این امر توسط سرور جدیدExtension SQL 2019 فعال میشود. این افزونه امکانات زیر را فراهم میکند:
- ساخت نمونههایی برای مدیریت مشترک Taskها.
- توانایی مرور HDFS، آپلود فایلها، پیشنمایش فایلها و ساختن دایرکتوریها.
- قابلیت ایجاد، باز کردن و اجرای نوتبوکهای سازگار با Jupyter.
- مجازیسازی دادههای Wizard برای ساده کردن ایجاد منابع دادهی خارجی.
معماری
کلاستر Big Data در سرور SQL، کلاستری از Containerهای Linux است که توسط Kubernetes هماهنگ شده است.
Kubernetes چیست؟
Kubernetes یک تنظیمکننده کانتینر Open Source است که میتواند پیشرفت Container را بر حسب نیاز اندازه بگیرد. موارد زیر برخی اصطلاحات مهم Kubernetes را مشخص میکند:
کلاستر: کلاستر Kubernetes مجموعه ای از ماشینهایی است که تحت عنوان Node شناخته میشوند. یک Node کلاستر را کنترل میکند و توسط Master Node انتخاب میشود. nodeهای باقیمانده Worker Node هستند. Kubernetes Master مسئول توزیع کار بین Workerها و مانیتورینگ صحت عملکرد کلاستر است.
Node : در واقع Nodeها برنامههای کاربردی Container شده را اجرا میکنند که ممکن است ماشین فیزیکی یا ماشین مجازی باشند. کلاستر Kubernetes ممکن است حاوی ترکیبی از ماشین فیزیکی و Nodeهای ماشین مجازی باشد.
Pod : واحد پیادهسازی تجزیه ناپذیر Kubernetes است، در واقع Pod، یک گروه منطقی از یک یا چند Container، و منابع مرتبط به آن است که برای اجرای یک برنامه کاربردی لازم است. هر Pod روی یک Node اجرا میشود و یک Node میتواند یک یا چند Pod را اجرا کند. Kubernetes Master به طور خودکار Podها را به Nodeهای موجود در کلاستر اختصاص میدهد.
در کلاسترهای Big Data ی سرور SQL، اصولا Kubernetes مسئول وضعیت کلاسترهای Big Data در سرور SQL است، بدین معنی که Nodeهای کلاستر را ایجاد و پیکربندی میکند، Podها را به Nodeها اختصاص میدهد و سلامت کلاستر را کنترل میکند.
معماری کلاسترهای Big Data
نمودار زیر اجزای یک کلاستر Big Data را برای سرور SQL نشان میدهد.
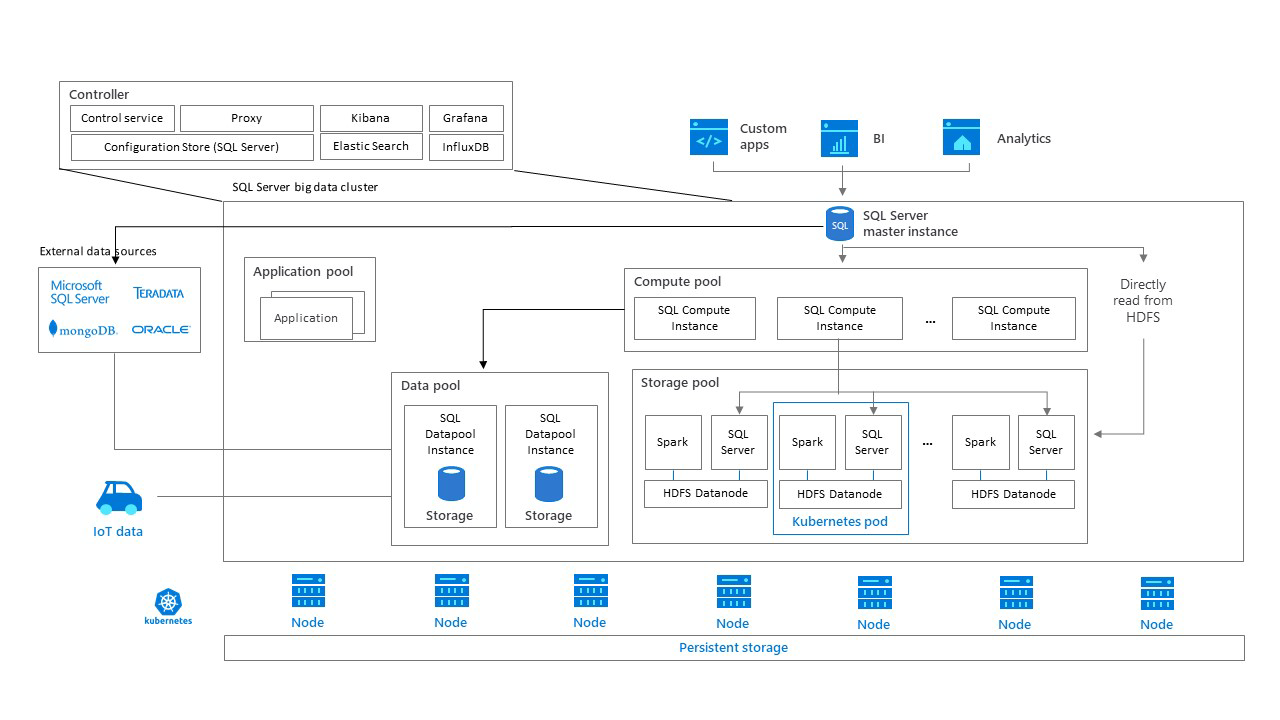
کنترلرها
کنترلر مدیریت و امنیت کلاستر را فراهم میکند که شامل سرویس کنترل، Configuration Store و دیگر سرویسهای سطح کلاستر مانند Kibana، Grafana و Elastic Search است.
مفهوم Compute pool
Pool محاسباتی یا Compute Pool، منابع محاسباتی را برای کلاستر فراهم میکند که شامل Nodهایی است که SQL Server را در Linux Pool اجرا میکنند. Podهای موجود در Pool محاسباتی برای Taskهای پردازشی خاص، به Instanceهای محاسباتی SQL تقسیم میشوند.
مفهوم Data Pool
Data Pool برای ماندگاری داده و Cache نمودن استفاده میشود. Pool داده شامل یک یا چند Pod است که سرور SQL را در Linux اجرا میکند و برای استفاده از دادهها از کوئریهای SQL یا Jobهای Spark استفاده میکند. بازارهای دادهی کلاستر Big Data در سرور SQL در Pool داده باقی میمانند.
Storage Pool
Storage Pool شاملPodهایStorage Pool متشکل از سرور SQL در Linux، Spark و HDFS است. تمام Storage Nodeهای موجود درکلاستر Big Data در سرور SQL، اعضای کلاستر HDFS هستند.
