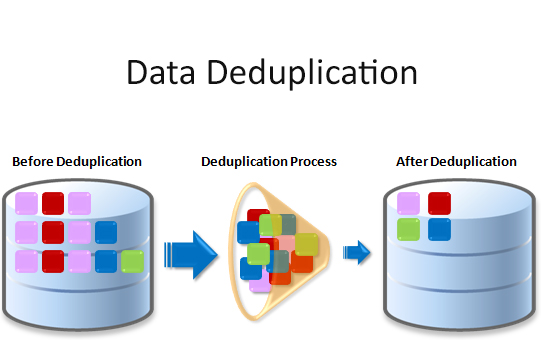
فرآیند Data Deduplication که به اختصار Dedup نیز نامیده میشود، یکی از ویژگیهای Windows Server 2016 میباشد که تأثیر دادههای اضافی بر هزینههای ذخیرهسازی را کاهش میدهد. این قابلیت در صورت فعالسازی، میتواند با بررسی دادههای موجود بر روی Volumeها از طریق جستجوی بخشهای تکراری آن موجب بهینهسازی فضای آزادِ بر روی Storage گردد. بخشهای تکراری از مجموعه دادهها تنها یکبار ذخیره شده و برای صرفهجوییِ بیشتر بهطور انتخابی فشرده میگردند. فرآیند Data Deduplication موجب بهینه شدن افزونگیها (Redundancy) میگردد و در عین حال Integrity دادهها را نیز حفظ میکند.

مزایای استفاده از Data Deduplication
در واقع Data Deduplication به مدیران Storage کمک میکند تا هزینههای مرتبط با دادههای تکراری را کاهش دهند. Datasetهای بزرگ اغلب دارای حجم زیادی از نسخههای تکراری و کپی میباشند که موجب افزایش هزینههای ذخیرهسازی داده میگردد؛ به عنوان مثال:
- در قسمت اشتراکگذاری فایلهای کاربران ممکن است نسخههای بسیار متعددی از فایلهای یکسان یا مشابه وجود داشته باشد.
- در بخش مجازیسازی ممکن است کاربران Guest در ماشینهای مجازی گوناگون، تقریبا مشابه باشند.
- Snapshotهای پشتیبانگیری ممکن است دارای تفاوتهای اندکی باشند.
صرفهجویی در فضای ذخیرهسازی با استفاده از قابلیت Data Deduplication به مجموعه دادهها (Dataset) یا بارکاری موجود بر روی Volume بستگی دارد. مجموعه دادههایی که دارای تعداد زیادی از نسخههای تکراری میباشند، با کمک این فرآیند میتوانیم نرخ بهینهسازی را تا 95 درصد افزایش داده و یا کاهش بیست برابری در میزان استفاده از Storage را فراهم کنیم. جدول پیش رو میزان صرفهجوییِ معمول حاصل از فرآیند Deduplication را برای انواع فایلها نشان میدهد.
| سناریو | محتوا | صرفهجویی معمول در فضا |
| فایلهای کاربران | فایلهای Office، عکسها، موسیقی، فایل ویدیویی و سایر موارد | 30 تا 50 درصد |
| موارد به اشتراک گذاشته شده | فایلهای باینری مربوط به نرمافزارها، فایلهای Cab، نمادها و سایر موارد
|
70 تا 80 درصد |
| مبحث مجازیسازی | فایلهای ISO، فایلهای مربوط به هارد دیسکِ مجازی و غیره | 80 تا 95 درصد |
| فایلهای عمومی به اشتراک گذاشته شده | شامل تمام موارد فوق | 50 تا 60 درصد |
موارد استفادهی Data Deduplication
در زیر به موارد استفاده از Dedup می پردازیم.
فایل سرورهای چند منظوره
فایل سرورهایی با کاربرد کلی میباشند که ممکن است هر کدام از بخشهای زیر را شامل شوند:
- فایلهای به اشتراک گذاشته شده توسط گروههای مختلف
- Home Folderهای کاربران
- بخش Work Folderها
- فایلهای Share شدهی گروه توسعه نرمافزار
این نوع از فایل سرورها گزینهی مناسبی برای اجرای Data Deduplication میباشد، چرا که معمولا کاربران زیادی تمایل به داشتن نسخههای متعددی از فایلهای یکسان میباشند؛ همچنین از آنجاییکه بسیاری از فایلهای Binary در فرآیند تشکیل معمولا بدون تغییر باقی میمانند، حوزه مرتبط با توسعه نرمافزار نیز از مزایای فرآیند Data Deduplication بهرهمند میگردد.
پیاده سازی زیرساخت دسکتاپ مجازی (VDI)
سرورهای VDI مانند سرویسهای Remote Desktop، به ارائه گزینهای معمول برای سازمانها جهت آمادهسازی دسکتاپ برای کاربران میپردازند. دلایل بسیاری برای کاربرد این تکنولوژی توسط سازمانها وجود دارد:
- پیادهسازی برنامههای کاربردی: امکان پیادهسازی سریع برنامههای کاربردی در سازمان ها میسر میشود. این قابلیت زمانی اهمیت مییابد که برنامههای کاربردی مرتبا به روزرسانی شده اما استفاده از آن به ندرت صورت میگیرد یا مدیریت آن دشوار میباشد.
- تجمیع برنامههای کاربردی: در صورت نصب و اجرای برنامههای کاربردی از طریق مجموعهای از ماشینهای مجازی با مدیریت مرکزی، میتوان نیاز به بهروزرسانی برنامههای کاربردی در کامپیوترهای Client را حذف نمود. علاوه بر این، گزینهی مذکور میزان پهنای باند موردنیاز جهت دسترسی به برنامههای کاربردی را کاهش میدهد.
- دسترسیِ Remote: امکان دسترسی کاربران به برنامههای کاربردیِ سازمان از طریق تجهیزاتی مانند کامپیوترهای خانگی، Kioskها، سختافزارهای کممصرف و سیستمعاملهای غیر Windowsای نیز فراهم میگردد.
- دسترسی به دفاتر شعب: پیادهسازی VDI موجب بهبود عملکرد برنامهها برای کارکنانی میشود که دسترسی به Data Storeهای متمرکز برای آنان ضروری میباشد. برنامههای کاربردی با دادهی متمرکز گاهی اوقات فاقد پروتکلهای سرور یا Client بهینهسازی شده برای اتصالات کمسرعت میباشند.
فرآیندهای پیادهسازی VDI از گزینههای مناسب برای Data Deduplication به شمار میروند، زیرا هارد دیسکهای مجازی که دسکتاپهای Remote را برای کاربران ایجاد میکنند، اساسا مشابه میباشند؛ به علاوه اینکه Data Deduplication به بهبود وضعیت فرآیندی تحت عنوان VDI Boot Storm نیز کمک مینماید. فرآیند VDI Boot Storm به افتِ عملکرد Storage در زمانی اطلاق میشود که تعداد زیادی از کاربران بهطور همزمان برای شروع کار به دسکتاپهای خود وارد میشوند.
اهداف پشتیبانگیری
برنامههای کاربردی پشتیبانگیری مانند برنامه های Backupگیری مجازی که شامل Microsoft Data Protection Manager یا به اختصار (DPM) می باشد، به دلیل قابلیت Duplication بین Snapshotهای پشتیبانگیری از گزینههای مطلوب برای فرآیند Data Deduplication به شمار میروند.
نحوهی عملکرد Data Deduplication
فرآیند Data Deduplication یا حذف دادههای تکراری در Server Windows بر مبنای دو اصل زیر شکل گرفته است:
1- فرآیند بهینه سازی نباید مانع از عملیات نوشتن بر روی دیسک گردد؛ Data Deduplication با استفاده از یک مدل Post-Processing به بهینهسازی دادهها میپردازد؛ بنابراین تمامی دادهها به صورت بهینه نشده بر روی دیسک نوشته شده و سپس در مرحلهی بعد از طریق فرآیند Data Deduplication بهینهسازی میگردند.
2- بهینهسازی نباید Access Semantics را تغییر دهد. کاربران و برنامههای کاربردی که به دادههای موجود در Volume بهینه شدهی Storage دسترسی دارند، به هیچ عنوان مطلع نیستند که فایلهای در دسترس آنها Deduplicate یا کپی برداری شده است.
به محض اجرای فرآیند Data Deduplication برای یک Volume مورد نظر از Storage، این فرآیند به منظور دستیابی به اهداف زیر شروع به فعالیت مینماید.
- شناسایی الگوهای تکراری در فایلهای موجود در Volume
- جابجایی یکپارچهی Portion یا Chunkها با علائم خاصی تحت عنوان Reparse Point که به یک کپی منحصربهفرد از Chunk اشاره میکند.
این فرآیند در چهار مرحله صورت میگیرد:
- اسکن فایل سیستم برای فایلهایی که مطابق با Policyهای بهینهسازی میباشند.

- تقسیم فایل به Chunkهایی با اندازههای متفاوت

- شناسایی Chunkهای منحصربهفرد
- استقرار Chunkها در Chunk Store و فشردهسازی آنها به صورت انتخابی
- جایگزینی جریان فایل اصلی از فایلهای بهینه سازی شده، با یک Reparse Point برای Chunk Store
در هنگام خوانده شدن فایلهای بهینهسازی شده، فایل سیستم به ارسال آنها از طریق یک Reparse Point به فیلتر فایل سیستم Data Deduplication یا Dedup.sys میپردازد. این فیلتر میتواند عملیات خواندن را به Chunkهای مربوطه هدایت نماید که جریانی را برای فایلها در Chunk Store ایجاد میکند. اصلاحات صورت گرفته بر روی انواع فایلهایی که فرآیند Deduplication بر روی آن اجرا شده است در وضعیت بهینهسازی نشده بر روی دیسک نوشته میشود و سپس در مرحله بعدی از اجرا با فرآیند بهینهسازی، بهینه میگردند.
کاربردهای Data Deduplication
انواع کاربردهای زیر میتواند دلیلی برای پیکربندیِ Data Deduplication برای بارهای کاری معمول باشد:
| نوع کاربرد | بار کاری ایدهآل | تفاوت |
| پیشفرض | فایل سرورهای چندمنظوره
|
1-بهینهسازی پسزمینه
2-سیاست بهینهسازیِ پیشفرض شامل:
|
| Hyper-V | سرورهای زیرساختِ دسکتاپ مجازی | 1. بهینهسازی پسزمینه
2.سیاست بهینهسازیِ پیشفرض
3. ایجاد تغییرات کوچک برای تعاملپذیری Hyper-V |
| پشتیبانگیری | برنامههای کاربردی برای پشتیبانگیری مجازی مانند Microsoft Data Protection Manager | 1.بهینهسازی اولویتها
2. سیاست بهینهسازی پیشفرض
3.ایجاد تغییرات کوچک برای تعاملپذیری Hyper-V با راهکارهای DPM یا شبه DPM |
