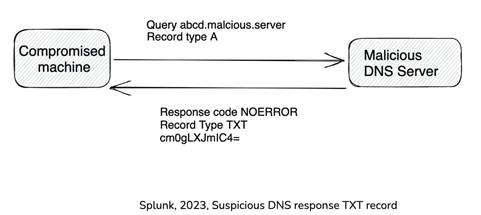
Domain Name System یا DNS یک پایگاهداده توزیع شده سلسلهمراتبی است که نام دامنهها را به آدرسهای IP نگاشت میکند و Tunneling یک پروتکل ارتباطی است که بستههای داده محصور شده را به طور ایمن بین شبکهها منتقل میکند. ازآنجاییکه پروتکل DNS برای ارتباطات شبکه اساسی و حیاتی است، اجازه داده میشود که از طریق فایروالها بدون بررسی دقیق مانند HTTPS ،FTP،SMTP برای فعالیتهای مخرب حرکت کند. عوامل مخرب با موفقیت توانستهاند از این مزیت برای ایجاد تونل DNS استفاده کنند که امکان انتقال داده بین شبکهها را فراهم میکند که فراتر از قصد اصلی پروتکل DNS است.

DNS Tunneling به مهاجمان اجازه میدهد یک کانال C2 ایجاد کنند که در آن درخواستهای DNS از قربانی بهعنوان ضربان قلب عمل میکند که نشان میدهد بدافزار هنوز شناسایی نشده است. یکی دیگر از کاربردهای برجسته DNS Tunneling، Command Injection است که در آن سرور DNS دستورها باینری یا کنترلی تعبیه شده در پاسخ رکورد DNS TXT را ارسال میکند که سپس توسط قربانی اجرا میشود.
بهعنوانمثال، بدافزاری که روی یک کلاینت اجرا میشود، یک درخواست DNS را به یک سرور DNS مخرب ارسال میکند و سرور تحت کنترل عوامل مخرب، یک پاسخ DNS را با کد NOERROR ارسال میکند. برخلاف کدهای پاسخ NXDOMAIN یا SERVFAIL، NOERROR نشان میدهد که درخواست با موفقیت پردازش شده است و پاسخ معمولاً یک آدرس IP دامنه درخواستی است. بااینحال، عوامل مخرب دستورها یا فایلهایی را در رکورد TXT بهعنوان یک پاسخ NOERROR بیضرر ارسال میکنند.
دستهبندی رکوردهای DNS TXT
ازآنجاییکه رکورد TXT ساختاری ندارد و برای اهداف کاملاً تعریف شده گسترشیافته است، لازم است بین استفاده مشروع و مشکوک از رکوردهای DNS TXT تفاوت قائل شویم. طبقهبندی رکوردهای DNS TXT مستلزم بررسی دادههای DNS تاریخی و نحوه استفاده از این رکورد در عمل است. یک مقاله تحقیقاتی اخیر، دادههای DNS را شامل 75 میلیارد رکورد DNS TXT که در طول سالها به طول میانجامد، برای تجزیهوتحلیل الگوهای متنی رایج و ثبت الگوهای جدید DNS TXT در نظر گرفت. رکوردهای DNS TXT با لیست کاملی از عبارات منظم دستههای مختلف مانند موارد زیر مطابقت داده شد و سپس دستههای مشابه در کلاسهای گستردهتر گروهبندی شدند.
بررسی راهکار Palo Alto Networks DNS Security
ویدیوهای بیشتر درباره DNS
بر اساس تجزیهوتحلیل محتوای متن، 83.35٪ از DNS TXT محتوای ضبط شده با الگوهای استاندارد و غیراستاندارد مانند تأیید ایمیل و دامنه مطابقت دارد. 15.48٪ حاوی محتوای بیضرر مانند سرورهای DNS یا تاریخ بود. 1.17 درصد باقیمانده از رکوردهای DNS TXT که با هیچ الگوی مطابقت نداشتند برای تجزیهوتحلیل عمیق بیشتر مفاهیم امنیتی در دسته «ناشناخته» گروهبندی شدند.
طبقهبندی رکوردهای DNS TXT بهعنوان یک مشکل ML
پس از دستهبندی، متوجه شدیم که DNS TXT برای چند رکورد مثلاً: v=spf1 برای ایمیل یا MS = ms63477054 برای تأیید با یک عبارت در لیست عبارات معمولی مطابقت ندارد؛ زیرا فضاهای اضافی، عدم تطابق حروف یا حتی وجود دارد. اشتباهات املایی علاوه بر این، رکوردهای حاوی تاریخ با قالبهای مختلف بهاشتباه در گزینه «سایر» دستهبندی شدند. ازآنجاییکه رکورد DNS TXT ساختاری ندارد، بیشتر مستعد ناسازگاری است و افزودن/تغییر regex یا متن پیشپردازش تنها میتواند تا حدودی دستهبندی اشتباه را بهبود می بخشد. اینجاست که یادگیری ماشینی ML میتواند در شناسایی الگوها در DNS TXT مفید و قوی باشد، حتی اگر کمی تحریف شده باشد و به ما کمک کند تا رکورد DNS TXT را بادقت در زمان واقعی طبقهبندی کنیم.
برای مشاوره رایگان و یا راه اندازی Splunk/SIEM و مرکز عملیات امنیت SOC با کارشناسان شرکت APK تماس بگیرید |
اکثر رکوردهای DNS TXT با اهداف کاملاً تعریف شده مطابقت داشتند، درحالیکه دسته «سایر» عمدتاً شامل کاراکترهای تک، ایمیل پایه 64، جاوا اسکریپت، کلیدهای عمومی/خصوصی، فایلهای اجرایی و دستورها بود. ما همه دستههای خوشخیم مانند ایمیل، تأیید، الگوها، کدگذاریشدن و متفرقه را در یک کلاس با برچسب is_unknown بهعنوان 0 و دسته «دیگر» با برچسب is_unknown بهعنوان 1 گروهبندی کردیم. 2 کلاس – is_unknown بهعنوان 0 یا 1. چند بخش بعدی به طور مفصل در مورد معماری مدل و ارزیابی مدل بحث خواهد کرد.
معماری مدل
ما فرایند مدلسازی را با ایجاد یک خط پایه، یک مدل رگرسیون لجستیک برای طبقهبندی رکوردهای DNS TXT آغاز کردیم. مجموعه ویژگی با تقسیم هر متن ورودی بر اساس فاصله و سپس کاراکترهای موجود در هر نشانه توسط یک پنجره کشویی از 1-4 کاراکتر ایجاد میشود. اگرچه دقت مدل 99.70% بود، اما دارای نرخ مثبت کاذب FPR بالای 0.22% بود. ما مدلی با FPR پایینتر را ترجیح میدهیم؛ زیرا در سناریوی واقعی، تنها درصد کمی از پاسخهای DNS حاوی سوابق TXT هستند و FPR بالاتر میتواند باعث خطای تشخیص شود.
ازاینرو، باتوجهبه اندازه مجموعهداده و ماهیت دادههای متنی، ما با معماریهای یادگیری عمیق DL مختلفی آزمایش کردیم که تمایل دارند با استفاده از ارزش از جاسازیهای کلمه، با دادههای متنی بهتر عمل کنند. در زیر معماری مدل طراحی شده آورده شده است.
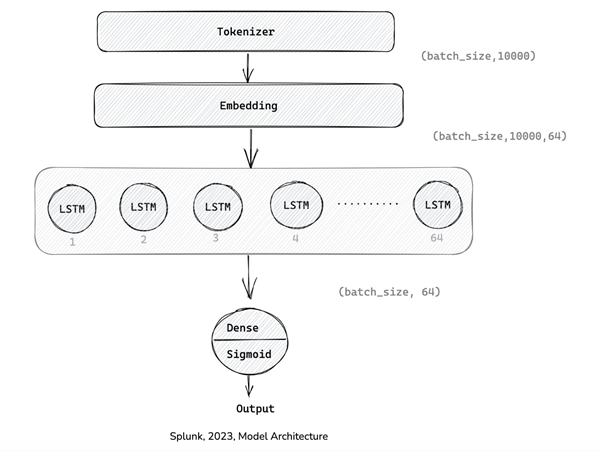
در مرحله اول، رکورد DNS TXT برای حذف فضاهای انتهایی، نقلقولها و قبل از ارسال به لایه Tokenizer به حروف کوچک تبدیل میشود. Tokenizer متن را به چند کلمه تقسیم میکند و توکنهایی را در یک پنجره کشویی با اندازه 1 تا 4 کاراکتر در هر کلمه ایجاد میکند. ازآنجاییکه اکثر رکوردهای DNS با اهداف کاملاً تعریف شده مطابقت دارند، 10000 کلمه برتر کلمات رایج را در آن رکوردهای DNS TXT ضبط میکنند.
بیشتر بخوانید: آشنایی با نحوه ی کار و چگونگی برقراری امنیت DNS
سپس خروجی لایه Embedding به لایه حافظه کوتاهمدت بلندمدت LSTM که یک نوع شبکه بازگشتی RNN است منتقل میشود. LSTM مدلهای دنبالهای هستند وابستگیهای یکطرفه بین توکنها را با استفاده از حالتهای پنهان ثبت میکنند. ازآنجاییکه هدف ما کاهش مثبت کاذب بود، یکلایه نسبتاً ساده LSTM با 64 واحد پیکربندی کردیم. علاوه بر این، نرخ انصراف 0.5 تنظیم شده است که به شبکه اجازه میدهد تا به طور موقت یک گره و اتصالات آن را به جلو و عقب در حین آموزش رها کند. این باعث ایجاد تغییراتی در شبکه میشود که بیش از حد برازش را کاهش میدهد.
لایه نهایی یکلایه متراکم است که خروجی لایه LSTM را مصرف میکند. این واحد منفرد مانند یک مدل رگرسیون لجستیک است که یک تابع فعالسازی سیگموئید را روی ترکیبی خطی از ویژگیهای ورودی برای تولید خروجی در مقیاس 0-1 اعمال میکند. خروجی یک امتیاز احتمال است که نشان میدهد چقدر احتمال دارد ورودی از کلاس «ناشناخته» باشد.
تنظیم پارامتر
ازآنجاییکه در طراحی یک مدل DL پارامترهای زیادی وجود دارد بهعنوانمثال، تعداد لایهها، تعداد واحدها، توابع فعالسازی و نرخ خروج، ما تنظیم هایپرپارامتر را انجام دادیم. تنظیم هایپرپارامتر تغییرات مدلها را با استفاده از ترکیبی از مقادیر پارامتر در یک محدوده مشخص ارزیابی میکند و یکی از مدلهای دارای عملکرد بهینه را انتخاب میکند.
آموزش و نتایج
برای اهداف آموزشی و آزمایشی، مجموعهداده را به ترتیب به مجموعهدادههای قطار، اعتبارسنجی و آزمایشی با اندازههای 80، 10، 10 درصد تقسیم کردیم. ازآنجاییکه آموزش مدلهای DL بر روی مجموعهدادههای بزرگ میتواند ساعتها طول بکشد، ما ازGPU هایی استفاده کردیم که در انجام تبدیلهای ریاضی پیشرفته برای محاسبات مدل ما تخصص دارند.
بیشتر بخوانید: 11 دلیل اصلی برای ارجاع DNSها به سرویس Cisco Umbrella
یک ماتریس سردرگمی عملکرد طبقهبندیکننده را با مقایسه مقادیر واقعی و پیشبینیشده توصیف میکند. با مقایسه عملکرد مدل DL با پایه، مدل LSTM DL بادقت 99.79 درصد بسیار خوب عمل کرده است. به طور قابلتوجهی FPR را از 0.22٪ به 0.11٪ کاهش داده است. نرخ مثبت واقعی (TPR) 99.05٪ برای 0.11٪ FPR است که نشان میدهد ما در موارد بسیار کمی اشتباه شلیک میکنیم. نرخ منفی واقعی 99.89% نشان میدهد که ما قادریم اکثر رکوردهای خوشخیم DNS TXT را با خطای طبقهبندی نادرست بسیار کم شناسایی کنیم.
گسترش
مدل از پیش آموزشدیده در اینجا موجود است و میتوان آن را بهراحتی با استفاده از Splunk App for Data Science and Deep Learning یا DSDL اجرا کرد.
برای کاربران Enterprise Security، تشخیص ESCU برای شناسایی سوابق DNS TXT مشکوک با استفاده از مدل از پیش آموزشدیده بهراحتی در ESCU نسخه 3.57.0 در دسترس است. تشخیص از فیلد پاسخ مدل دادههای وضوح شبکه با نوع پیام «response» و record_type بهعنوان «TXT» بهعنوان ورودی مدل استفاده میکند. این تشخیص منجر به پاسخهای DNS میشود که دارای ‘is_suspicious_score’ > 0.5 هستند. آستانه روی 0.5 تنظیم شده است و قابلتنظیم است.
شناسایی رویدادهای خطر را برای هر رکورد DNS TXT مشکوک شناسایی شده ایجاد میکند. سپس رویدادهای ریسک توسط چارچوب هشدار مبتنی بر ریسک RBA امنیتسازمانی پردازش میشوند تا موارد قابلتوجهی ایجاد شود. پست اخیر وبلاگ ما را بخوانید که با جزئیات صحبت میکند.
با دردسترسبودن گسترده ابزارهای تونلسازی و ماهیت عمدی توسعهپذیر پروتکل DNS، حملات تونلسازی DNS، بهویژه با استفاده از تزریق دستور از طریق پاسخ DNS TXT، در حال افزایش هستند. برای شناسایی موفقیتآمیز این حملات، تمایز بین استفاده مشروع و مشکوک از رکوردهای DNS TXT با تجزیهوتحلیل محتوای متنی رکورد ضروری است. در این پست، نحوه دستهبندی پاسخهای DNS TXT را به دستههای کاملاً مشخص و سپس استفاده از یک رویکرد مبتنی بر ML برای طبقهبندی دقیق پاسخهای TXT بهعنوان مشکوک یا غیر مشکوک موردبحث قرار دادیم. با وجود ماهیت متن آزاد، مدل یادگیری عمیق LSTM بادقت 99.05٪ از تمام رکوردهای DNS TXT مشکوک را با FPR بسیار پایین 0.11٪ تشخیص میدهد و در نتیجه هشدارهای نادرست را کاهش میدهد. دقت مدل 99.79 درصد نشان میدهد که اطمینان خوبی در پیشبینیها وجود دارد. مدل LSTM بر روی یک مجموعهداده بزرگ آموزشدیده و برای عملکرد بهینه تنظیم شده است. مدل از پیش آموزشدیده را میتوان با استفاده از DSDL مستقر کرد و با یک دستور ساده «apply» در جستجوهای SPL استفاده کرد.
